스물두번째 날: 북마크 사이트를 소장용 EPUB으로 만들기
저자
@white_catz - 무한야옹교교주, 신도들 사이에서는 교주님으로 통한다. 이름만 들으면 알만한 므흣한 매체와 게임들의 번역을 수행한 일본어 번역 스페셜리스트. 주로 하얀고양이, 흰괭이라는 닉을 사용하며, 가끔씩은 agcraft라는 닉을 사용하기도 한다.
시작은 사건 사고로
항상 모든 일은 계획대로 되지만은 않습니다.
그래 이것으로 하자! 왠지 재미 있을 것 같아!
의욕 넘치게 선정했던 첫 주제는 "Dropbox로 어쩌구 저쩌구..." 였습니다.
하지만 Dropbox의 여신은 처음부터 제게 거칠기만 했습니다.
샘플 코드 작성 중에 OAuth 인증 문제가 발생했고
일단은 WWW::Mechanize를 사용해서 해결했지만,
이젠 다시 접근 토큰(access token)의 권한 문제로 지지부진한 상태에 이르렀죠.
(마감 시간은 다가오는데!)
미소 짓는 InstaPaper 여신
안 피우겠다던 담배를 물고 휴대폰에 책꽃이한 블로그들을 보기 시작했습니다. 그러다 문득 '이런 기사를 저장해서 보는건 어떨까?'라는 생각이 스치면서 떠오른 것은 바로 화제의 중심인 EPUB! 하지만 형태가 다양한 블로그 기사를 정리해서 일관된 형태로 제공해야 할텐데 이것도 만만치는 않은 작업임에 분명합니다. 궁시렁대던 그 때 iPhone에서 아름답게 후광을 내뿜는 여신이 있었으니 바로 InstaPaper Free 버전이었습니다!
전략짜기
원하는 최종 결과물은 웹사이트의 내용을 전자책에 담는 것입니다. 웹 사이트의 형식을 일관되게 정리하는 일은 InstaPaper를 사용해 InstaPaper의 결과물을 이용합니다. 전체적인 작업의 절차는 다음과 같습니다.
- InstaPaper에 로그인
- InstaPaper에 저장할 블로그 기사 URI전달
- 이전 단계에 저장한 텍스트 형태의 블로그 글 및 사용된 자원을 PC에 저장
- 저장한 블로그 글을 InstaPaper에서 삭제
- 저장한 내용 중 URI 정리 및 불필요한 태그 및 스크립트 삭제
- EPUB 형태로 묶기
- 전자책 확인
일련의 과정을 쉽게 처리하기 위해 작은 작업 단위로 나눕니다.
- Instapaper에 인증 후 API를 이용해서 기사글을 저장
- API로 저장한 웹사이트 글 및 관련 자원을 가져와 PC에 저장
- 저장한 웹사이트 글 중 원격지로 연결된 자원의 주소를 변경하고 필요없는 태그와 스크립트를 제거
- 저장한 웹사이트의 글 및 자원을 EPUB으로 묶은 후 EPUB뷰어로 확인
사용하는 CPAN 모듈
사용하는 CPAN 모듈의 목록은 다음과 같습니다. 모듈별로 자세한 사용법은 각각의 문서를 참고하세요.
- Data::Dumper
- EBook::EPUB
- File::Basename
- Image::Info
- URI
- URI::Escape
- WWW::Instapaper::Client
- WWW::Mechanize
- Web::Scraper
WWW::Instapaper::Client
CPAN의 WWW::Instapaper::Client 모듈을
사용하면 쉽게 Instapaper의 API를 사용할 수 있습니다.
다음은 Instapaper에 인증 후 API를 이용해서 기사글을 저장하는
instapaper.pl 스크립트입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #!/usr/bin/env perluse 5.010;use strict;use warnings;use WWW::Instapaper::Client;#Initializemy $username = 'email@emaildomain';my $password = 'password';#todo heremy $paper = WWW::Instapaper::Client->new( username=>$username, password=>$password,);my $result = $paper->add( url => shift, title => shift, selection => q{},);if (defined $result) { say $result->[0]; say $result->[1];}else { warn $paper->error."\n";} |
실행할때 명령줄에서 URI과 제목을 입력받아서 URI에 해당하는 내용을 Instapaper에 저장을 요청합니다. 제목이 없다면 해당 URI의 메타 데이터를 사용합니다. 요청의 결과는 URL을 인코딩한 URI와 제목입니다. 실행 결과는 다음과 같습니다.
1 2 3 | $ ./instapaper.pl http://aero.springnote.com/pages/914354http://aero.springnote.com/pages/914354"scope codeblock, my,local,our - aero님의 노트" |
이제 Instapaper에서 결과를 확인해보세요.
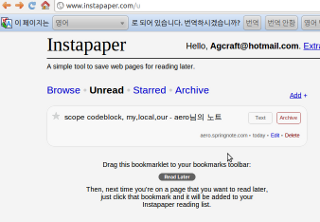
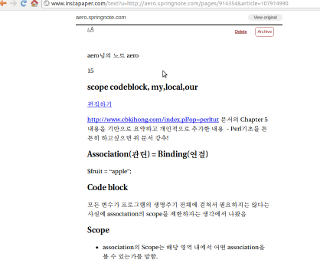
참 쉽죠잉~~
Instapaper에서 PC로
Instapaper는 등록한 글을 모바일 기기에서 보기 좋도록 어느정도 재가공을 해주는데 우리는 이 기능을 이용할 것이므로 이제 Instapaper에 저장한 글을 로컬 PC에 저장하겠습니다. 코드를 살펴보죠.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | #!/usr/bin/env perluse 5.010;use strict;use warnings;use autodie;use URI;use URI::Escape;use Web::Scraper;use WWW::Mechanize;#Intializemy $url = shift;my $username = 'email@emaildomain';my $password = 'password';my $mech = WWW::Mechanize->new;#todo heremy $res = $mech->get($instapaper_login);if ( $mech->success ) { my $form = $mech->current_form; $form->value( username => $username ); $form->value( password => $password ); $res = $mech->submit; if ( $res->is_success ) { $res = $mech->get($instapaper_unread); $url = URI->new($url)->as_string; $url =~ s/([^A-Za-z0-9-.])/sprintf("%%%02X", ord($1))/seg; if ( $res->decoded_content =~ /href="(\/text\?u=$url&article=\d+)/ ) { open my $fh, '>', 'result.html'; binmode $fh; print $fh $res->decoded_content; close $fh; } }} |
Instapaper는 단순한 형태로 페이지가 구성되어 있습니다.
인증을 위해 username과 password를 폼에 채워준 후 로그인을 진행합니다.
브라우저로 접속해보면 로그인 후에 자동으로 unread 페이지로 이동하므로
비슷하게 스크립트에서도 수동으로 해당 페이지를 열어줍니다.
unread 페이지에는 Instapaper에 저장한 여러 기사글이 있습니다.
원하는 글을 고르기 위해 이전 작업 단계의 결과인 URI를 키로 사용해서
원하는 문서의 링크 주소를 찾습니다.
하지만 Instapaper는 URL 인코딩을 수행하므로
그대로는 키로 사용할 수 없으므로 형식에 맞게 키가 될 URI를 인코딩해줍니다.
여기서는 URI 모듈과 단순한 정규식을 사용합니다.
이렇게 얻은 URI를 웹사이트 주소와 결합해 문서를 요청한 후
결과를 result.html 파일에 저장합니다.
프로그램을 실행하면 실행한 디렉터리에 result.html 파일이 보일 것입니다.
글에 엮인 그림은?
저장한 result.html에는 그림 파일과 같은 외부 자원이 엮여있을 것입니다.
역시 전자책으로 묶는다면 이미지도 같이 넣어야 그럴듯하겠죠?
그럼 이번에는 result.html에서 그림 파일 주소를 가져와보죠.
이번 크리스마스 달력 6일자 기사를
참고한 부분이 많으니 여러분도 놓치지 말고 꼭 읽어보세요.
다음은 Web::Scraper 모듈을 이용해 링크 주소만 추출해 다운로드하는 코드 조각입니다.
1 2 3 4 5 6 7 | my $download_link = scraper { process 'img','link[]'=>'@src';};my $result = $download_link->scrape($res->decoded_content);my $content = $res->decoded_content;image_download( @{$result->{link}} ); |
Web::Scraper는 CSS 선택자를 이용해서 요소에 접근해 자료를 가져옵니다.
구현한 image_download() 사용자 함수는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | sub image_download { my ( @image_links ) = @_; for my $image ( @image_links ) { my $ua = LWP::UserAgent->new; my $filename = basename($image); $res = $ua->get($image); if ($res->is_success) { open my $fh, '>', $filename; binmode $fh; print $fh $res->content; close $fh; } }} |
크리스마스 달력 6일자 기사와 비교했을때
basename 함수를 사용해서 전체 경로중 파일 이름만 뽑아내서
저장할 이름으로 사용하는 점이 다릅니다.
이로써 글에 엮인 그림 파일을 내려받는 스크립트를 작성했습니다.
스크립트를 실행하면 그림파일은 스크립트를 실행한 경로에 저장됩니다.
드디어 출판이다!
지금까지의 결과물을 모두 종합해서 EPUB형태의 전자책을 만들 차례입니다.
실제 EPUB으로 만들어주는 epub() 함수는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | sub epub { my ( @image_links ) = @_; my $epub = EBook::EPUB->new; $epub->add_title('이곳에 제목을 넣어 주세요'); $epub->add_author('이곳에 저자를 넣어 주세요'); $epub->add_language('ko'); $epub->add_identifier('9999999999', 'ISBN'); for my $image ( @image_links ) { my $el = basename($image); my $result = image_info($el); if(!defined($result->{error})) { my $filetype = $result->{file_media_type}; $epub->copy_image($el, $el, $filetype); } } $epub->copy_xhtml('result.html', 'result.html'); $epub->pack_zip('myebook.epub');} |
크리스마스 달력 6일자 기사와 비교했을때
이미지에 MIME Type을 적용하기 위해 image_info를 사용한 점이 다릅니다.
image_info로 온 이미지에 오류가 발생하면 $result->{error}에
오류가 저장됩니다.
마지막으로 $epub->pack_zip를 이용해서 전자책을 만듭니다!
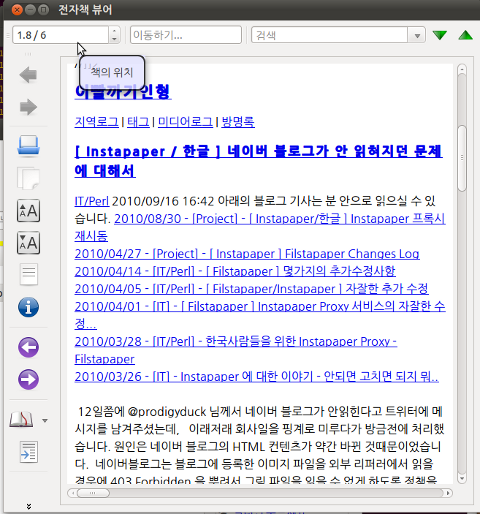
결과
다음은 지금까지의 코드 조각을 모두 모아 실행해서 만들어낸 EPUB 전자책입니다. 잘 보이시나요? ;-)
정리하며
현재 이렇게 작성한 EPUB 전자책의 경우 iBook에서 지원하지 않는 스크립트나 태그가 있을 경우 책 자체를 읽을 수 없는 문제가 있기도 합니다. 또한 기사를 쓰는 도중에 다시금 테스트를 해보니 다운로드가 잘되던 이미지 기반의 몇몇 사이트의 경우 제대로 다운로드가 되지 않았습니다. 트래픽 유발로 인해 사이트쪽에서 차단이 된 것이 아닐까 추측합니다. 조금은 전략적으로 스크립트를 운용해야겠죠? ;-)
 거침없이 배우는 펄
거침없이 배우는 펄