열두번째 날: 웹툰을 한 눈에 내 만화 프로젝트 Manaba
저자
@rumidier - 충남 서산 출신의 야생마. SILEX 문하에서 Perl 수련 중인 Perl Monks. SILEX에서 밥과 음료를 흡입하며 사막화에 적극 앞장서고 있다.
시작하며
바쁜 일상 속에 웹툰은 한줄기 빛과 같습니다. 하지만 즐겨 보는 웹툰을 어디까지 봤는지 일일이 기억하기는 어려운 일이죠. 일일이 웹툰 홈페이지에서 가서 열람하면 되는 일이긴 하지만, 그렇게 대놓고 화면을 띄우고 보기에는 사장님 눈치가 보입니다. 최신 웹툰이 나왔는지 오매불망 뒤적거리다보면 돌아오는 것은 사나운 눈초리... 누구보다 빠르게 남들과는 다르게 웹툰을 보고 싶다는 마음(네, 사실은 귀찮아서 입니다)을 가지고 만화를 보려면 어떻하면 좋을까요?
준비물
필요한 모듈은 다음과 같습니다.
- CPAN의 File::Path 모듈
- CPAN의 File::Slurp 모듈
- CPAN의 LWP::UserAgent 모듈
- CPAN의 URI 모듈
- CPAN의 Web::Scraper 모듈
- CPAN의 YAML::Tiny 모듈
데비안 계열의 리눅스를 사용하고 있다면 다음 명령을 이용해서 모듈을 설치합니다.
1 2 3 4 5 6 7 | $ sudo apt-get install \ libfile-path-perl \ libfile-slurp-perl \ libwww-perl \ liburi-perl \ libweb-scraper-perl \ libyaml-tiny-perl |
직접 CPAN을 이용해서 설치한다면 다음 명령을 이용해서 모듈을 설치합니다.
1 | $ sudo cpan File::Path File::Slurp LWP::UserAgent URI Web::Scraper YAML::Tiny |
사용자 계정으로 모듈을 설치하는 방법을 정확하게 알고 있거나
perlbrew를 이용해서 자신만의 Perl을 사용하고 있다면
다음 명령을 이용해서 모듈을 설치합니다.
1 | $ cpan File::Path File::Slurp LWP::UserAgent URI Web::Scraper YAML::Tiny |
각 웹툰의 정보 수집하기
그럼 각각의 포탈 사이트별로 어떻게 원하는 웹툰 정보를 가져올까요? 대표적으로 많은 사람들이 이용하는 네이버 웹툰, 다음 웹툰, 네이트 웹툰 세 사이트를 기준으로 살펴보겠습니다. 다른 사이트를 추가한다 하더라도 비슷한 방식으로 접근하면 됩니다.
Daum 웹툰
다음 웹툰은 특정 한 회의 경로만 알아도 웹툰의 모든 정보를 가져올수 있습니다. 다음 웹툰은 회차 별 번호도 무작위인 것이 특징이며, 특정 회차의 웹툰에 접속할 때 해당 웹툰 아이디 정보없이 회차 아이디만 있어도 접근할 수 있다는 것이 특징입니다.
1 2 3 4 5 6 7 8 9 | my $daum = scraper { process( 'div.episode_list > div.inner_wrap > div.scroll_wrap > ul > li', 'items[]', scraper { process 'a.img', link => '@href'; process 'a.img', title => '@title'; } );}; |
네이트 웹툰
네이트 웹툰은 셀렉트 박스로 각 회차를 구분하기 때문에
특정 회차의 주소만 있다면 모두 읽어올 수 있습니다.
http://URL/webtoon/detail.php?btno=31337에서 고유 아이디(31337, 구두 웹툰)가
존재하지만 각 회차 별 번호는 무작위인 것이 특징입니다.
1 2 3 4 5 6 7 8 9 | $nate = scraper { process( 'div.wrap_carousel div.thumbPage div.thumbSet dd', 'items[]', scraper { process 'a', link => '@href'; process 'img', title => '@alt'; } );}; |
네이버 웹툰
네이버 웹툰은 의외로 신경쓸 부분이 많습니다.
상대적으로 장편 만화가 많기 때문에 페이지 넘김 등의 고려를 해야해서
간단하게 구현하기 위해 첫 페이지의 최신 정보만 읽어들이는 방법을 택했습니다.
다행히도 해당 웹툰의 아이디만 알고 있다면 회차 정보는 1부터 순차적으로 증가하므로
for ( 1 .. <최신id> )와 같은 식으로 원하는 만큼 URL 생성이 가능합니다.
1 2 3 4 5 6 7 8 | $naver = scraper { process( 'table.viewList tr td.title', 'items[]', scraper { process 'a', link => '@href'; } );}; |
Manaba 설정하기
만화를 손쉽게 보도록 도와주는 우리의 프로젝트 이름은 Manaba 정도가 딱 적절할 것 같습니다. Manaba 프로그램은 보고 싶은 만화를 목록으로 보여줘야 할텐데, 프로그램에게 목록을 넘겨주는 방법으로 간편하게 설정 파일을 사용합니다. 설정 파일의 종류로는 윈도에서 주로 쓰는 INI, 아파치 설정 파일 CONF, 복잡한 자료를 보이기에 좋은 XML, 최근 널리 쓰이는 JSON, XML보다 조금 더 간편한 YAML 등이 있습니다. 편집하는 사람의 편의를 위해 YAML을 사용하도록 하죠.
manaba.yml을 만드는 작업 자체는 어렵지 않습니다.
적어도 현재 네이버와 다음, 네이트에 대해서는 사용자가
웹툰의 코드와 대표 이미지를 추출하는 작업이 필요합니다.
site야 이미 어느 포탈에서 서비스하고 있는지에
대한 부분이므로 당연히 알고 있을테구요.
manaba.yml 파일은 크게 두 개의 항목을 가집니다.
sitewebtoon
보통 웹툰은 서비스하는 포탈 사이트 별로 형식이 다르지만,
동일한 포탈 사이트에서 제공되고 있다면 대부분은 일정한 규칙을 가집니다.
이런 포탈 사이트의 종류와 해당하는 규칙을 정의하는 곳이 site 항목입니다.
그리고 관리하려는(편하게 보려는) 만화의 목록은 webtoon 항목에 기입하도록 합니다.
다음은 manaba.yml 설정 파일에서 관리하는 site 항목의 내용입니다.
1 2 3 4 5 6 7 8 9 10 | site: daum: start_url: http://cartoon.media.daum.net/webtoon/viewer/%s webtoon_url: http://cartoon.media.daum.net/webtoon/viewer/%s nate: start_url: http://comics.nate.com/webtoon/detail.php?btno=%s webtoon_url: http://comics.nate.com/webtoon/detail.php?btno=%s&bsno=%s naver: start_url: http://comic.naver.com/webtoon/list.nhn?titleId=%s webtoon_url: http://comic.naver.com/webtoon/detail.nhn?titleId=%s&no=%s |
각각의 사이트는 start_url 항목과 webtoon_url 항목을 가집니다.
추후 다음, 네이트, 네이버 이외의 웹툰 사이트를 등록한다면
약간의 분석을 거친 후 추가하면 됩니다.
다음은 manaba.yml 설정 파일에서 관리하는 webtoon 항목의 내용 중 일부입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | webtoon: dieter: name: 다이어터 site: daum code: 10362 image: http://i1.cartoon.daumcdn.net/svc/image/U03/cartoon/U620854C4D5B251707 noblesse: name: 노블레스 site: naver code: 25455 image: http://imgcomic.naver.com/webtoon/25455/thumbnail/title_thumbnail_20100614120245_t125x101.jpg kudu: name: 구두 site: nate code: 31337 image: http://crayondata.cyworld.com/upload/series/31337_m.gif |
이제 다음과 네이버, 네이트 웹툰이라면 얼마든지 관리하고(보고?)
싶은 만큼 설정파일에 추가하면 됩니다.
각각의 만화는 자신만의 고유 ID 하부에 name, site, code, image 항목을 가집니다.
site와 code 부분은 정확하게 기입해야지만 Manaba가 제대로
처리를 해줄 수 있습니다. name과 image는 화면에 보이기 위한
부분으로 잘못 입력한다고 해도 실행에 문제는 없지만 웹툰 이름이
제대로 보이지 않는다던가 또는 웹툰 대표 이미지가 제대로 보이지 않는
문제가 있을 수 있습니다.
설정파일 자체가 간결한 만큼 특별한 설명이 더 필요할 것 같지는 않습니다.
작성한 manaba.yml 설정 파일을 읽어 들이려면
CPAN의 YAML::Tiny 모듈을 사용합니다.
1 2 3 4 | sub load_manaba { my $yaml = YAML::Tiny->read( config->{manaba} ); $CONFIG = $yaml->[0];} |
마구 긁어오기!
웹 페이지의 정보를 긁어올 수 있는 라이브러리나 Perl 모듈은 무척 많습니다.
하지만 웹 포탈의 경우 디자인과 HTML 구조가 수시로 변하기 때문에
가능하면 손쉽게 원하는 HTML 요소의 값을 추출할 수 있는 방법을 사용하는 것이 유리합니다.
CPAN의 Web::Scraper 모듈을 이용하면 CSS 셀렉터 방식이나
XPath 방식을 이용해서 HTML 특정 요소를 쉽게 찾을 수 있습니다.
정규 표현식을 이용하는 것보다는 상대적으로 많이 느리지만
사이트의 변화에 따라 발빠르게 대응할 수 있다는 것이 매력입니다.
또한 웹을 긁어올 때 일부러 해당 사이트에 과부하를 주지 않기 위해
지연 시간을 주기도(sleep $time) 하는데 Web::Scraper의 속도 자체가
느리기 때문에 아무래도 긁는 입장에서는 약간의 지연이 발생하므로
조금 안심되는 면도 있습니다.
각각의 포탈 사이트 별로 Web::Scraper 모듈을 이용해서 페이지를 긁은 후
회차 관련 정보를 추출하도록 합니다.
네이트 웹툰에 대해 처리하는 코드는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | sub update_nate_link { my ( $id, @links ) = @_; ... my @chapters = sort { my $page_no_a = 0; my $page_no_b = 0; $page_no_a = $1 if $a =~ m/^(\d+)$/; $page_no_b = $1 if $b =~ m/^(\d+)$/; $page_no_a <=> $page_no_b; } map { m{viewer/(\d+)$}; } @links; ...} |
네이버 웹툰과 다음 웹툰도 기본적인 형식은 비슷하지만,
map을 이용해서 링크 주소에서 회차 정보를 긁어오는
정규표현식 부분만 조금씩 다릅니다.
Let's Dance!
원하는 웹툰의 첫 주소도, 최신 주소도 알았고 이제 남은 것은 화면에 뿌려주기만 하면 됩니다. 아무래도 간단하게 만들 때는 웹 어플리케이션으로 만드는 것이 UI를 수정한다거나 Perl과 연동하기도 좋은 것 같습니다. 그렇다면 Perl의 마이크로 웹 프레임워크인 Dancer를 사용해서 UI 구현을 마무리하죠.
컨트롤러는 단 두 개만 만들겠습니다.
기본 페이지를 의미하는 /, 즉 인덱스용 컨트롤러 하나와
강제로 사용자가 등록한 웹툰의 정보를 갱신(Web::Scraper를 이용해서)하는
update 컨트롤러를 생성합니다.
- /
- /update/:id?
/ 컨트롤러는 뷰 단에 넘겨주기 위한 데이터를 생성하기 위한 처리를 수행합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | get '/' => sub { my $webtoon = $CONFIG->{webtoon}; my @items = map { my $item = $webtoon->{$_}; $item->{id} = $_; $item->{first} = q{} unless $item->{first}; $item->{last} = q{} unless $item->{last}; $item; } sort keys %$webtoon; my $ptr = 0; my @rows; while ( $items[$ptr] ) { my @cols; for my $i ( 0 .. 9 ) { last unless $items[$ptr]; push @cols, $items[$ptr]; ++$ptr; } push @rows, \@cols; } template 'index' => { rows => \@rows, };}; |
update 컨트롤러는 id를 받아서 특정 회차만 갱신할 수도 있고
id를 넘겨주지 않는 경우 모든 웹툰의 회차 정보를 갱신합니다.
1 2 3 4 5 6 7 8 9 10 11 12 | get '/update/:id?' => sub { my $id = param('id'); if ($id) { update($id); } else { update_all(); } redirect '/';}; |
웹툰의 정보를 긁어오는 함수는 update_all()과 update() 함수입니다.
update_all() 함수는 내부적으로 update() 함수를 호출하므로
update() 함수를 간략하게 살펴보죠.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | sub update { my $id = shift; return unless $id; my $webtoon = $CONFIG->{webtoon}; return unless $webtoon; my $site_name = $webtoon->{$id}{site}; return unless $site_name; my $scraper = $SCRAPERS->{ $site_name }; return unless $scraper; my $site = $CONFIG->{site}; return unless $site; my $start_url = sprintf( $site->{ $site_name }{ 'start_url' }, $webtoon->{$id}{ 'code' }, ); my $items = $scraper->scrape( URI->new( $start_url ) )->{items}; my @links = map { $_->{link} } @$items; given ( $site_name ) { update_daum_link($id, @links) when 'daum'; update_naver_link($id, @links) when 'naver'; update_nate_link($id, @links) when 'nate'; }} |
update() 함수는 다시 각각의 사이트 별로 웹툰을 처리하기 위한 함수로 이동합니다.
각각의 함수에서는 앞에서 보았던 Web::Scraper 모듈을 이용해서
원하는 웹툰 회차 정보를 추출합니다.
Web::Scraper를 사용하기 때문에 적절하게 지연 시간을 주지 않으면
포탈 사이트로부터 사용하는 아이피가 블록 당할 수 있으므로 주의하도록 합니다.
필요하다면 update_all() 또는 update() 함수에
sleep $time 처럼 지연 시간을 적절하게 주도록 합니다.
현재 구현상 Manaba가 최초에 Dancer 웹 어플리케이션으로 실행될 때
모든 웹툰의 정보를 긁어옵니다.
웹툰의 양이 많으면 많을수록 정보를 긁어오는데 드는 비용이 커지므로
페이지가 갱신 될때마다 정보를 갱신하기 보다는 각각의 웹툰 별로
갱신할 수 있도록 /update 컨트롤러에서 id를 인자로 받고 있음을 유의해주세요.
네이버는 괴로워...
거의 다 작업이 끝나갈 무렵 네이버의 웹툰 대표 이미지가 보이지 않기 시작했습니다. (이런! 아까까지만 해도 잘 보였는데!!) 여러번의 검색 및 테스트 결과 네이버가 정책적으로 외부 주소에서 자신의 이미지를 열람하는 것을 막아 놓았다는 심증을 굳히게 됩니다. 아마도 트래픽의 폭증을 막기 위한 방안으로 생각되는데 국내 1위 대형 포탈임을 감안할때 생각보다 쪼짜.. ... 한 것 같습니다. IP 블럭 당하지 않은 것이 다행이군요...;;;
그래서 프로그램 상에서 이미지를 바로 보여주는 것이 아니라 다운로드 받아서 로컬 하드 디스크에 저장해서 보여주기로 정책을 선회합니다. 필요한 모듈은 다음과 같습니다.
웹툰의 이미지를 로컬에 저장하는 fetch_webtoon_image() 함수는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | sub fetch_webtoon_image { my $ua = Web::Scraper::user_agent; return unless $ua; return unless $CONFIG; my $webtoons = $CONFIG->{webtoon}; return unless $webtoons; make_path('public/images/webtoon'); for my $id ( keys %$webtoons ) { my $file = "public/images/webtoon/$id"; next if -f $file; my $response = $ua->get( $webtoons->{$id}{image} ); if ($response->is_success) { write_file( $file, $response->content ); }} |
Manaba로 만화봐!
드디어 완성되었습니다! 약간의 그리드 CSS를 추가해서 1280 해상도를 사용하는 시스템에서 무리없이 볼 수 있도록 했습니다.
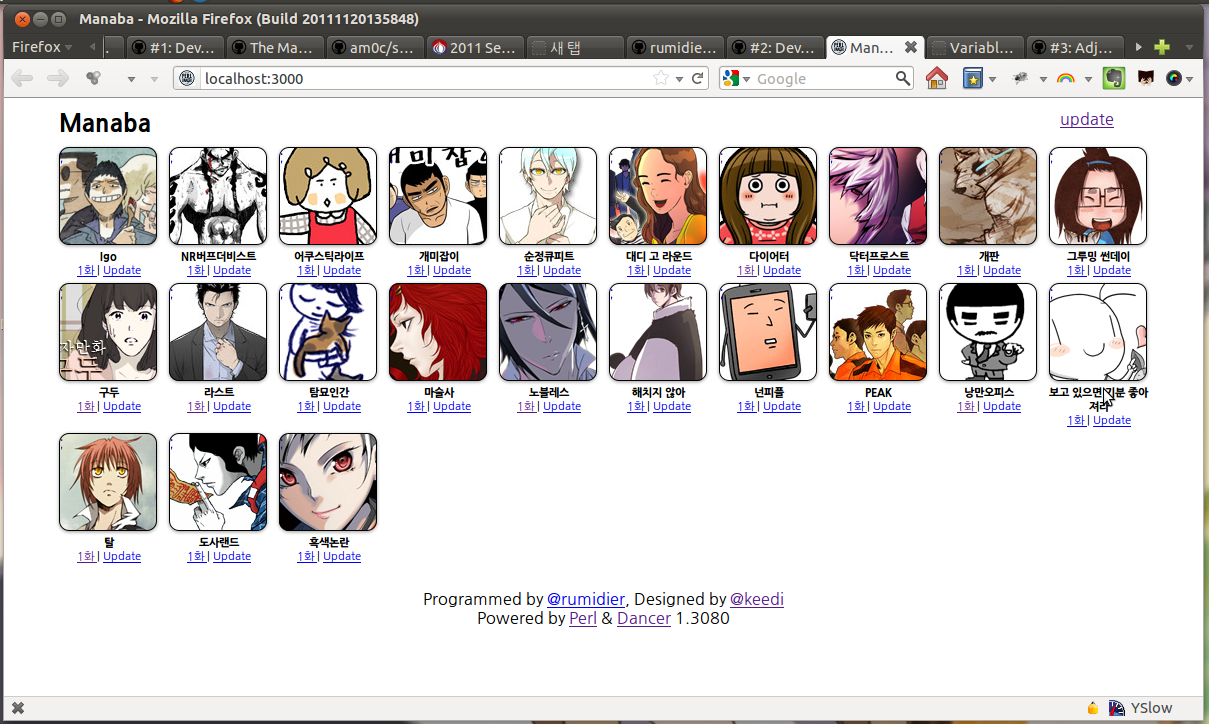 그림 1. Manaba로 만화봐! (원본)
그림 1. Manaba로 만화봐! (원본)
Don't forget fork me on GitHub!! ;-)
정리하며
최근 웹툰 목록 보기라던가, SNS와의 연동 등 추가해야 할 사항은
GitHub를 통해 조금씩 발전시키려고 합니다.
이렇게 Web::Scraper와 YAML::Tiny, Dancer 세 개의 모듈을 이용해
간단하게 웹 어플리케이션을 만들어 보았습니다.
저처럼 MVC 개념에 익숙하지 않으면 직관적인 CGI에 비해 적응하는데
약간의 시간은 걸리지만, Perl과 CPAN 모듈, Dancer와 조합한
웹 어플리케이션 제작 환경은 정말 놀랄 정도로 간단합니다.
여러분들도 마음 속에 담아 두었던 아이디어를 Perl을 통해 한번 구현해보면 어떨까요? ;-)
후기
마이크로 프로젝트로 2주 가량의 시간을 산정하고 진행했으나 처음의 원대한 포부로 인해 생각보다 많은 시간이 걸렸습니다. 결국 4~5여 일을 남겨두고 지금 정도의 시스템으로 명세를 대폭 축소하고 복잡한 부분이나 추가 기능은 다음 릴리스를 위해 미루기로 했습니다. 기사 투고는 물론 일정과 관련해서 조금 더 시간 관리에 대해 생각해보게 되었네요.
글을 쓸 수 있게 도와주신 @y0ngbin님과 @am0c님, @mintegrals님께 감사드립니다. 또 막판에, 비루한 웹 UI에 희망을 불어넣어 준 @keedi님께 고마운 마음을 전합니다. Manaba로 만화봐! 프로젝트는 proof-of-concept 단계의 예제에 가깝지만, 사용하시는 분들과 Perl 및 Dancer를 공부하시려는 분들께 도움이 되길 바래봅니다.
 거침없이 배우는 펄
거침없이 배우는 펄
Articles by Seoul Perl Mongers
Illustrated by Hyunsu Park, Designed by Hojung Youn, Edited by Hojung Youn & Keedi Kim