
열번째 날: dcmon: While You Were Sleeping
저자
@berise - @대전(펄 미팅에 한번 가보고 싶지만 여건상 못가는 지방남), 테니스, github:berise, berise at gmail.com
시작하며
소개해 드릴 내용은 지난 펄크리스마스 달력에도 여러 번 등장한 웹 이미지를 저장하는 스크립트입니다. 크리스마스 즈음이 되면 어김없이 찾아오는 스크립트입니다. 원래 신문 기사나 dcinside 등의 갤러리 글을 긁는 용도였지만, 지금은 모니터링으로 용도가 변경 되었죠. 그래서 이름이 dcmon입니다. 네! 여러분이 생각하는 그것! 일명 짤방 수집기가 맞습니다. 기존의 스크립트들과 비교해 최신 글을 모니터링하여 가져올 수 있다는 점이 약간의 차이겠군요. 우리가 잠을 자는 사이에 많은 글들이 생성되고 삭제되지요. :)
처음에 dcmon은 Python으로 시작하였으나 Python의 정규 표현식 및 urllib2의 처리 방식이 썩 마음에 들지 않아 Perl로 변경해서 구현하게 되었습니다. Python 버전을 포함한 전체 코드는 GitHub의 저장소에서 내려받을 수 있습니다.
준비물
필요한 모듈은 다음과 같습니다.
Encode 모듈과 threads 모듈의 경우 펄 코어 모듈이므로 별도로 설치할 필요는 없습니다.
직접 [CPAN][cpan]을 이용해서 설치한다면 다음 명령을 이용해서 모듈을 설치합니다.
1 2 3 4 | $ sudo cpan \ LWP::Simple \ WWW::Mechanize \ Web::Scraper |
사용자 계정으로 모듈을 설치하는 방법을 정확하게 알고 있거나 [perlbrew][home-perlbrew]를 이용해서 자신만의 Perl을 사용하고 있다면 다음 명령을 이용해서 모듈을 설치합니다.
1 2 3 4 | $ cpan \ LWP::Simple \ WWW::Mechanize \ Web::Scraper |
처음에는 외부 모듈과의 의존성을 줄이려고 LWP 모듈나 Scraper 모듈을 사용하지 않고 직접 HTML을 파싱해
필요한 링크나 파일 이름을 분리했지만 이번에 코드를 수정하면서 선진(?) 모듈을 도입했습니다.
전체 흐름
우선 전체적인 흐름의 순서는 다음과 같습니다.
- 갤러리 모니터링
- 게시물 목록 가져오기
- 최신 글 가져오기
- 파일 이름 링크 분리
- 이미지 다운로드
dcmon은 설정 파일을 이용해 모니터링할 갤러리를 관리합니다.
dcmon.cfg 파일에 모니터링할 겔러리 목록을 개행 문자로 구분해서 넣습니다.
#은 주석으로 인식합니다.
갤러리 목록은 해당 웹페이지의 URL에 표기되는 게시판의 이름을 기록해야 합니다.
다음은 설정 파일의 예입니다.
1 2 3 4 5 6 | ## dcmon.cfg#comedy_new2game_classic#leagueoflegends |
파일에서 읽은 갤러리 목록을 이용해 이미지를 저장할 경로를 만듭니다. 그 후 갤러리마다 별도의 쓰레드를 생성해 게시판을 모니터링합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | for my $gallery (@lines) { next if $gallery =~ /^#/; chomp $gallery; setup_directory($gallery); print "Monitoring $gallery\n"; my $thread = threads->create( \&run_dcmon_with_given_name, $gallery ); push(@threads, $thread);}for my $t (@threads) { $t->join();} |
갤러리의 게시물 번호를 가져온 후 새로운 게시물이 있는지 판단 후 새로운 게시물이 있을 경우 해당 게시물을 가져옵니다. dcinside의 경우 너무 자주 웹페이지를 읽을 경우 차단되므로 5 ~ 15초 가량 쉬어가며 모니터링합니다.
1 2 3 4 5 6 7 8 9 | while (1) { my @new_list = get_recent_number_list($gallery); $curr_index = determine_most_recent_page_number( \@new_list, \@prev_list ); $image_count = find_and_get_images($gallery, $new_list[$curr_index]); @prev_list = @new_list; sleep( 5 + rand(10) );} |
첨부 파일 다운로드
첨부 파일을 다운로드하는 부분은 dcmon에서 가장 중요한 부분(존재의 이유)입니다. :) HTML 구조상 브라우저에 보이는 이미지와 파일 이름이 분리되어 있습니다. 따라서 각 페이지에서 첨부 파일의 이름과 이미지 링크를 추출해야 합니다. dcinside의 게시물에서 첨부 파일은 다음처럼 구성되어 있습니다.
1 2 3 4 5 | <div class="box_file"><p><b>blablabla <span>(1)</span></b></p><ul class="appending_file" style="width:1086px; overflow:hidden; word-wrap:break-word;"><li class="icon_pic"><a href="http://image.dcinside.com/download.php?id=3dbcd4&no=29bcc427b18177a16fb3dab004c86b6f202dc30d4da4684a3e1ac6a7c7ebd7c987208b949b05d1e6c1b5eb4f7980e1ec361160615f&f_no=74e58173b48607f237e98fec4083736dc6302f1fd1fc44dacabf19050a6fd757ff7c2ae69f9e06">981514_496996270395434_1700987382_o.jpg</a></li></ul></div> |
이제 Web::Scraper 모듈의 도움을 얻을 때 입니다.
앞의 HTML 코드 조각의 경우 Web::Scraper 모듈을 이용해 간단히 추출할 수 있습니다.
추출하는 코드는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 | sub scrape_href_links { my $html_content = shift; my $html_element = scraper { process ".icon_pic > a", "html[]" => 'HTML', "text[]" => 'TEXT'; }; # get html text based on div class="con_substance" my $res = $html_element->scrape( $html_content ); return $res->{text};} |
dcinside 갤러리 웹페이지 내부의 이미지 링크는 다음처럼 구성되어 있습니다.
1 2 3 4 5 | <!-- con_substance --><div class="con_substance"><div class="s_write"><div id='zzbang_div' style='display:none;'></div><pre></pre><table border="0" width="100%"><tr><td><p><br></p><p style="text-align: left;"><img src="http://dcimg1.dcinside.com/viewimage.php?id=3dbcd4&no=29bcc427b18177a16fb3dab004c86b6f202dc30d4da4684a3e1ac6a7c7ebd7c987208b949b05d1e6c1b5eb4f7980e1ec361160615f" class="txc-image" style="clear:none;float:none;" /></p><p>blablablabla<br></p></td></tr></table></div> |
추출하는 코드는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | sub scrape_links { my $html_content = shift; my $html_element = scraper { process ".con_substance", html => 'HTML'; }; # [] for plural my $img_element = scraper { process "img", "src[]" => '@src'; }; # get html text based on div class="con_substance" my $res = $html_element->scrape( $html_content ); # get img src link which shows real image (in javascript pop window) my $res2 = $img_element->scrape( $res->{html} ); return $res2->{src};} |
이렇게 파일 이름과 이미지 링크를 추출을 완료하면 가장 중요한 작업이 끝난 셈입니다. 이제 게시물이 포함된 웹 페이지와 첨부 파일을 가져와보죠. 종종 파일 이름이 없는 경우도 있는데 이 경우는 무시하고 건너 뛰도록하죠. 다음 함수는 원본 파일의 이름을 그대로 사용해서 저장하기 때문에 파일 이름이 겹치는 경우 기존 파일이 삭제됩니다. 이를 방지하려면 파일 이름을 유일하게 만들어 저장하는 기능이 필요합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | sub find_and_get_images { my ( $gallery, $url ) = @_; my $html_contents = get($url); my $h_filenames = scrape_href_links($html_contents); my $h_links = scrape_links($html_contents); # http://zzbang.dcinside.com/pad_temp.jpg is basic image # for an article without any image attached if ( !defined($h_filenames) ) { print "[$gallery] No image\n" if $opt{debug}; return; } my $file_count = @{$h_filenames}; my $link_count = @{$h_links}; my $image_count = 0; print "# of files : ($file_count), # of links : ($link_count)\n" if $opt{debug}; for (my $i = 0; $i < $file_count; $i++) { my $filename_p; $filename_p = encode( 'cp949', $h_filenames->[$i] ); if ( $opt{debug} ) { print " - download $filename_p\n"; print "$h_filenames->[$i], $h_links->[$i]\n"; } download_and_save_as( $h_filenames->[$i], $h_links->[$i] ); } return $file_count;} |
마지막으로 주어진 파일이름과 링크를 이용하여 이미지를 다운로드 및 저장하는 부분이 남았네요.
이것 저것 시험하다 보니 wget, mechanize, LWP 각각을 사용해서 다운로드하는 코드를 만들어버렸네요.
각각의 코드를 참고하고 입맛에 맞는 것으로 사용하면 됩니다.
LWP를 사용하는 부분은 예전 펄 석가탄신일 달력의 내용을 참고했습니다.
파일 인코딩은 환경에 맞게 변환하면 됩니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | sub download_and_save_as { my ( $filename, $link ) = @_; my $USE_WGET = 0; my $USE_MECHANIZE = 0; my $USE_LWP = 1; my $filename_p = encode( 'cp949', $filename ); # 저장할 위치 지정 $filename_p = "dcmon/temp/$directory_name/$filename_p"; if ($USE_WGET) { my $cmd_wget = "wget \"$link\""; print "Execute $cmd_wget\n"; # download with wget system $cmd_wget; } elsif ($USE_MECHANIZE) { my $image = get($link); next unless defined $image; open my $fh, ">", $filename_p; binmode $fh; print $fh $image; close $fh; } elsif ($USE_LWP) { my $ua = LWP::UserAgent->new( agent => 'Mozilla/5.0 ' . '(Windows; U; Windows NT 6.1; en-US; rv:1.9.2b1) ' . 'Gecko/20091014 Firefox/3.6b1 GTB5' ); my $res; eval { $res = $ua->get($link); }; if ($@) { warn $@; next; } open my $fh, ">", $filename_p; binmode $fh; print $fh $res->content; close $fh; } my $filesize = -s $filename_p if -e $filename_p; print " + $filename_p($filesize Bytes)\n" if $opt{debug};} |
다음 코드는 Web::Scraper 모듈을 사용하기 이전 정규 표현식을 이용해 파일 이름과 링크를 추출했던 코드입니다.
dcinside의 웹페이지가 개편되면서 코드는 더 이상 동작하지 않습니다.
참고 삼아서 살펴보세요. :)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | sub extract_filenames { my $html_contents = shift; my $pattern = "<li class=\"icon_pic\"><a href=.*>(.*?.*?)<\/a>"; my @files = $html_contents =~ /$pattern/gi; for my $file (@files) { print "extract_filenames : $file\n" if $opt{debug}; } return @files;}sub extract_links { my $html_contents = shift; my $pattern = "<li class=\"icon_pic\"><a href=\"(.*)\">.*?.*?<\/a>"; my @links = $html_contents =~ /$pattern/gi; for my $link (@links) { print "extract_links : @links\n" if $opt{debug}; } return @links;} |
실행 그리고 한계
실행하면 현재 디렉토리에 dcmon 디렉터리를 만들어 이 디렉토리 하부에 이미지들을 저장합니다.
그림 1은 터미널에서 실행한 결과를 갈무리한 것입니다.
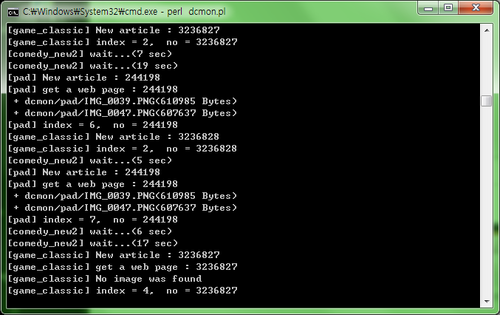 그림 1. go dcmon! (원본)
그림 1. go dcmon! (원본)
아무래도 차단되는 것을 방지하기 위해 시간차를 주기 때문에 그 시간차 사이에 생성되었다가 지워지는 글은 놓칠 수 밖에 없습니다. dcinside에서 API를 지원해주기 전까지는 어쩔수 없는 구조적인 문제이므로 이정도는 넘어가도록 하죠. 우린 관대하니까요. :)
큰 무리없이 사용할 수 있는 스크립트지만 간혹 모니터링하다가 죽어버리는 경우가 발생합니다. (흠, 밤새 돌아야 하는 코드인데...) 아직 분석을 하지 않아 무슨 문제로 죽는지는 모르지만 언제나 패치는 환영합니다. :)
정리하며
한동안 사용하지 않던 코드를 다시 꺼내 실행 가능하게 수정하는 것은 역시 쉽지 않네요.
그래도 펄의 유연함 덕분에 빠른 시간 안에 수정 하고 실행을 가능했답니다.
LWP, Mechanize, Scraper 등 멋진 모듈들이 있어 펄을 더욱 즐겁게 사용할 수 있는 것 같습니다. :)
- 크리스마스 달력이란
- 펄 크리스마스 달력 #2010
- 펄 크리스마스 달력 #2011
- 펄 크리스마스 달력 #2012
- Perl Advent Calendar
- Perl 6 Advent Calendar
- Perl Catalyst Advent Calendar
- Perl Dancer Advent Calendar
- Future Advent Calendar
- 일본 Perl Advent Calendar
- 일본 Mojolicious Advent Calendar
- Sysadmin Advent Calendar
- 펄.kr
- 네이버 펄 카페
- IRC #perl-kr 채팅
- 한국펄워크샵 2008



{kind=link}
{kind=link}
Artwork by
@namanvara,
Hyungsuk Hong
& Inkyung Park.
Designed by
Hojung Youn
& Keedi Kim.
Articles by
Seoul Perl Mongers.
Edited by
Keedi Kim.
Hosting generously sponsored by
Yuni Kim.
Sponsored by
SILEX.
.-''' __ __
/ \/ \/ \
=-_- |
\. -____- / \
// /|| ''
//| //||
== = == ==