
스물네번째 날: DAG 기반의 태스크 스케줄러
저자
@saillinux - 마음씨 좋은 외국인 노동자, 현재 페이스북에서 옵 엔지니어로 재직 중이다. 거침없이 배우는 펄의 공동 역자, Perl로 MMORPG를 만들어보겠다는 꿈을 갖고 있지만 요즘은 현실과 타협해 시스템 트레이딩에 푹 빠져있는 Perl덕후, 건강을 최고의 신조로 여기고 있다.
시작하며
지금까지 우리는 자동화를 할때면 스크립트를 작성하거나 모듈을 작성해 여러 군데에 적용해 일을 처리하곤 하죠. 허나 더욱 고난이도의 일을 처리하다보면 태스크 의존성을 고려해야 하는 경우가 많습니다. 이를 스크립트를 작성해서 처리하다보면 다른 곳에서도 같은 코드를 작성하게 되고 이런 패턴을 일일히 모듈화 해서 새로운 스크립트에 적용하여 작성하는 것도 번거롭습니다. 펄의 Graph 모듈과 DAG 알고리즘을 조합해 태스크의 의존성을 해결할 수 있는 스케줄러를 만들어보면 어떨까요?
준비물
필요한 모듈은 다음과 같습니다.
직접 CPAN을 이용해서 설치한다면 다음 명령을 이용해서 모듈을 설치합니다.
1 | $ sudo cpan Capture::Tiny Graph JSON |
사용자 계정으로 모듈을 설치하는 방법을 정확하게 알고 있거나 perlbrew를 이용해서 자신만의 Perl을 사용하고 있다면 다음 명령을 이용해서 모듈을 설치합니다.
1 | $ cpan Capture::Tiny Graph JSON |
전략
근래 관심을 두게 된 방법론이 Flow-based programming입니다만 쉽게 적용 할수 없는 이론이라 그중에 몇 가지 아이디어만을 적용해 프로그램을 작성해 보기로하죠.
- Unix 철학을 숙지해 하나의 기능만을 완벽히 잘하는 컴포넌트를 구현 합니다. (예. ls, grep, awk, sed, xargs, ...)
- 이렇게 해서 구현한 컴포넌트를 서로 연결시켜 프로그램을 작성하게끔 도와주는 툴을 만듭니다. 이를 통해 컴포넌트 재사용 및 가용성을 개선합니다.
- 프로그램 규모가 커지면 소수의 인원 만으로 기능 구현이 힘들어집니다. 간단하고 직관적인 프레임워크를 제공해 여러 인원들이 쉽게 컴포넌트를 작성해 수고를 덥니다.
그림 1과 같이 태스크 의존성을 존중하여 프로그램을 실행 해야 하는 서비스를 만들어 보도록 하겠습니다.
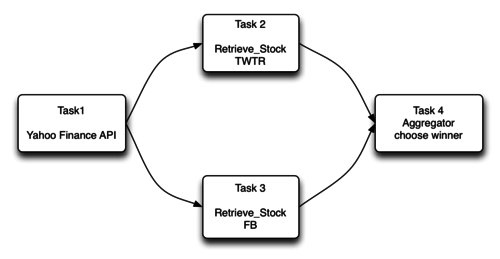 그림 1. stock winner test (원본)
그림 1. stock winner test (원본)
물론 스크립트 하나로 작성하면 편하겠지만 지속적으로 추가되는 기능 사항을 소화해내기 위해 새로운 시도를 해보죠! :)
컴포넌트 준비
그림 1의 서비스는 야후 파이낸스에서 지정한 주식 중 어떤 것이 가장 많은 이득을 냈는지 비교하는 서비스입니다. 첫번째 태스크는 야후 파이낸스 API 서비스를 이용해 요즘 관심을 가지고 보고있는 주식인 Twitter, Facebook, Tesla등의 데이터를 가져 옵니다.
1 | $ curl 'http://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20yahoo.finance.quote%20where%20symbol%20in%20(%22TWTR%22%2C%22FB%22%2C%22TSLA%22%2C%22XOM%22)&format=json&diagnostics=true&env=store%3A%2F%2Fdatatables.org%2Falltableswithkeys&callback=' |
데이터를 무사히 가져 오면 Task2,3은 retrieve_stock 컴포넌트를
실행해 Twitter와 Facebook의 변화값을 참고해 가져옵니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | sub retrieve_stock { my ( $self, $args ) = @_; my $task = $args->{preds}[0]; my ( $stock, $field ) = @{ $args->{params} }; my $json = decode_json( $nodes{$task}{stdout} ); my @quotes = @{ $json->{query}{results}{quote} }; for my $entry (@quotes) { if ( $entry->{symbol} eq $stock ) { $nodes{$self}{stdout} = $entry->{$field}; $nodes{$self}{exit} = 0; } } $nodes{$self}->{exit} = 1 unless exists $nodes{$self}{stdout};} |
이렇게 해서 얻은 변화값을 비교해 어떤 주식이 오늘 이득을 많이
볼 수 있었는지 aggregator 컴포넌트를 통해 출력 합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | sub aggregator { my ( $self, $args ) = @_; my %changes = (); for my $task ( @{ $args->{preds} } ) { my $stock = $nodes{$task}{params}[0]; my $change = $nodes{$task}{stdout}; $changes{$stock} = $change; } my @sorted = sort { $changes{$b} <=> $changes{$a} } keys %changes; my $winner = $sorted[0]; $nodes{$self}{stdout} = $winner; warn "OUTPUT: The winner is $winner by change $changes{$winner}\n";} |
이제 컴포넌트 준비는 끝났습니다. :)
자료구조
이를 구현 하기 위해서는 각 태스크가 사용하는 컴포넌트와 스케줄러를 설계해야겠죠. 첫째로 태스크 의존성을 저장할 수 있는 자료구조가 필요합니다. 여기서는 비유향 방향 그래프(Directed Acyclic Graph, 줄여서 DAG)라는 그래프 구조체를 이용해 각 태스크(node)와 의존성(edge)을 저장하겠습니다. CPAN의 Graph 모듈은 모든 언어를 통틀어 현존하는 그래프 라이브러리 중에서는 최고라고 자부할 수 있을 정도로 그래프를 다루는데 있어 필요한 모든 기능을 제공합니다.
첫째로 해야할 일은 그래프 만들기입니다.
이를 위해 $g0라는 그래프 구조체를 생성하고 여기에 node로
정의된 태스크를 vertex로 그래프에 저장합니다.
1 | my $g0 = Graph->new; |
각 노드는 해시 키로 지정했으며 각 노드 구조체는 다음과 같은 속성을 가집니다.
- action: 실제로 태스크가 수행해야 하는 외부 명령어 혹은 콜백 함수를 정의 합니다.
- params: action을 실행하기 위해 필요한 인자를 정의 합니다.
- start, end time: 태스크가 실행 시작 했던 시점과 끝난 시점을 저장합니다.
- state: 현재 태스크의 상태를 저장합니다.(예.
WAITING,RUNNING,DONE,FAIL) - stdout, stderr, error: action의 수행 결과물들을 나중에 명령 수행 후 저장합니다.
지금까지 정의한 자료구조를 펄로 표현하면 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | my %nodes = ( Task1 => { action => 'curl', params => [ "http://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20yahoo.finance.quote%20where%20symbol%20in%20(%22TWTR%22%2C%22FB%22%2C%22TSLA%22%2C%22XOM%22)&format=json&diagnostics=true&env=store%3A%2F%2Fdatatables.org%2Falltableswithkeys&callback=" ], start_time => 0, end_time => 0, state => WAITING, }, Task2 => { action => \&retrieve_stock, params => [qw/ TWTR Change /], start_time => 0, end_time => 0, state => WAITING, }, Task3 => { action => \&retrieve_stock, params => [qw/ FB Change /], start_time => 0, end_time => 0, state => WAITING, }, Task4 => { action => \&aggregator, params => [], start_time => 0, end_time => 0, state => WAITING, },); |
이 자료구조를 그래프에 더해야겠죠.
1 2 3 4 | # add each task to the graph as nodefor my $task ( keys %nodes ) { $g0->add_vertex($task);} |
그리고 의존성을 edge로 표현하면 다음과 같습니다.
1 2 3 4 5 6 | my %edges = ( Task1 => [ "Task2", "Task3" ], Task2 => ["Task4"], Task3 => ["Task4"], Task4 => [],); |
이제 실제로 각각의 태스크를 연결해보죠. :)
1 2 3 4 5 | for my $task ( keys %edges ) { for my $dep ( @{ $edges{$task} } ) { $g0->add_edge( $task, $dep ); }} |
그래프 객체인 $g0를 출력해보면 그래프의 구조를 확인할 수 있습니다.
1 | print "INFO: The graph is $g0\n"; |
출력 결과는 다음과 같습니다.
1 | INFO: The graph is Task1-Task2,Task1-Task3,Task2-Task4,Task3-Task4 |
조금 감이 오시나요? :)
그래프 유효성 점검
태스크를 실행하기 앞서 그래프가 유효한지 검증이 필요합니다. 검증하는 항목은 다음과 같습니다.
- 그래프가 directed 그래프인지 확인. 즉 노드와 노드 사이를 연결해 주는 모든 선이 방향성을 가지고 있는지 확인.
- 그래프 자체에 순환을 가지는 의존성이 있는지 확인. 그래프에 순환 구조가 있다면 무한 루프에 빠질 수 있음.
- 태스크를 시작 하는 지점이 여러군데가 존재하는지 확인.
시작 지점의 경우 시작 지점이 여러군데인 것이 문제는 아니지만 간단한 구현을 위해 제한하도록 하죠.
시작 지점은 노드들 중 in_degree가 없는, 즉 의존성이 없는 태스크가 하나 이상 존재 한다면
시작 지점이 여러군데인것으로 간주 할 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | sub validate { my $dag = shift; die "FATAL: graph is not a directed and acyclic\n" unless $dag->is_dag; die "FATAL: graph contains a cycle\n" if $dag->is_cyclic; my @heads; my @tasks = $dag->vertices; for my $task (@tasks) { my $in_degree = $dag->in_degree($task); next if $in_degree; push @heads, $task; } die "FATAL: more than one execution start points\n" if @heads > 1;} |
스케줄러 구현
유효성 검증을 통과했다면 이제 태스크를 실행 시켜주는 스케쥴러를 구현해보죠. 그래프에 위상정렬(topological sorting)을 실행해 수행해야 하는 태스크의 순서를 가져옵시다.
1 2 3 4 5 6 | sub scheduler { my $dag = shift; my @ts = $dag->topological_sort; ... |
순서가 정해진 태스크를 @ts에 저장하여 이를 하나 하나 실행합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | for my $task (@ts) { if ( $dag->in_degree($task) ) { warn "INFO: check whether predecessors of [$task] were executed successfully\n"; for my $predecessor ( $dag->predecessors($task) ) { my $state = $nodes{$predecessor}{state}; die "FATAL: $task.$predecessor: failed\n" if $state == FAIL; die "FATAL: $task.$predecessor: wrong exiting\n" unless $state == DONE; warn "INFO: $task.$predecessor: success\n"; } } else { warn "INFO: $task is the head, starting this task now\n"; } ...} |
먼저 시작되어야 하는 태스크가 무엇인지 확인 하기 위해 in_degree로 확인합니다.
즉 in_degree가 0이면 시작 지점으로 간주해 바로 실행 합니다.
의존성을 지니고 있는 태스크가 있다면 predecessors 함수를 사용하여 현재
태스크가 실행 되기 전에 필요한 태스크를 리스트 하여 해당 태스크의 상태를 확인 합니다.
그중에 하나라도 실패한 태스크가 있다면 동작을 중단합니다.
현재 실행 해야 하는 태스크의 노드 구조체를 가져온후 상태값과 시작 시간을 업데이트 해줍니다.
1 2 3 4 5 | my $node = $nodes{$task};warn "INFO: running task [$task]\n";$node->{state} = RUNNING;$node->{start_time} = time; |
태스크가 수행해야 하는 작업과 이를 위해 필요한 인자값및 이전에 실행 되었던 태스크 목록을 준비합니다.
1 2 3 | my $action = $nodes{$task}->{action};my @params = @{ $nodes{$task}->{params} };my @predecessors = $dag->predecessors($task); |
$action은 콜백함수는 물론 외부 명령도 처리할 수 있도록 구현합니다.
1 2 3 4 5 6 7 8 9 10 11 | if ( ref $action eq 'CODE' ) { $action->($task, { preds => \@predecessors, params => \@params, });}else { @$node{ 'stdout', 'stderr', 'exit' } = capture { system $action, @params; };} |
여기서 @predecessors를 인자로 전달하는 것은 이전 태스크의 결과물을 참조하기 위해서입니다.
$action이 코드 레퍼런스가 아니라면 외부 명령어로 간주하고 실행합니다.
여기서는 크리스마스 달력 열두번째 날: 펄에서 외부명령어 실행 시키기 기사에서 소개된
Capture::Tiny 모듈을 이용해 표준 출력, 표준 오류, 결과 상태를 간단히 가져옵니다.
수행이 끝났다면 완료 시간과 수행 결과 상태를 갱신합니다.
1 2 | $node->{end_time} = time;$node->{state} = !$node->{exit} ? DONE : FAIL; |
실행 결과
실행 결과는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | INFO: The graph is Task1-Task2,Task1-Task3,Task2-Task4,Task3-Task4INFO: Task1 is the head, starting this task nowINFO: running task [Task1]INFO: check whether predecessors of [Task3] were executed successfullyINFO: Task3.Task1: successINFO: running task [Task3]INFO: check whether predecessors of [Task2] were executed successfullyINFO: Task2.Task1: successINFO: running task [Task2]INFO: check whether predecessors of [Task4] were executed successfullyINFO: Task4.Task3: successINFO: Task4.Task2: successINFO: running task [Task4]OUTPUT: The winner is TWTR by change +4.53 |
전체 코드
지금까지 작성한 DAG 알고리즘 기반의 스케줄러의 전체 코드는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 | #!/usr/bin/env perluse v5.14;use strict;use warnings;use Capture::Tiny ':all';use Graph;use JSON;use constant { WAITING => 0, RUNNING => 1, DONE => 2, FAIL => 3,};my %nodes = ( Task1 => { action => 'curl', params => [ "http://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20yahoo.finance.quote%20where%20symbol%20in%20(%22TWTR%22%2C%22FB%22%2C%22TSLA%22%2C%22XOM%22)&format=json&diagnostics=true&env=store%3A%2F%2Fdatatables.org%2Falltableswithkeys&callback=" ], start_time => 0, end_time => 0, state => WAITING, }, Task2 => { action => \&retrieve_stock, params => [qw/ TWTR Change /], start_time => 0, end_time => 0, state => WAITING, }, Task3 => { action => \&retrieve_stock, params => [qw/ FB Change /], start_time => 0, end_time => 0, state => WAITING, }, Task4 => { action => \&aggregator, params => [], start_time => 0, end_time => 0, state => WAITING, },);my %edges = ( Task1 => [ "Task2", "Task3" ], Task2 => ["Task4"], Task3 => ["Task4"], Task4 => [],);my $g0 = Graph->new; # there is a song called zero g love in Macross# add each task to the graph as nodefor my $task ( keys %nodes ) { $g0->add_vertex($task);}# connect each taskfor my $task ( keys %edges ) { for my $dep ( @{ $edges{$task} } ) { $g0->add_edge( $task, $dep ); }}warn "INFO: The graph is $g0\n";validate($g0);scheduler($g0);sub validate { my $dag = shift; die "FATAL: graph is not a directed and acyclic\n" unless $dag->is_dag; die "FATAL: graph contains a cycle\n" if $dag->is_cyclic; my @heads; my @tasks = $dag->vertices; for my $task (@tasks) { my $in_degree = $dag->in_degree($task); next if $in_degree; push @heads, $task; } die "FATAL: more than one execution start points\n" if @heads > 1;}sub scheduler { my $dag = shift; my @ts = $dag->topological_sort; for my $task (@ts) { if ( $dag->in_degree($task) ) { warn "INFO: check whether predecessors of [$task] were executed successfully\n"; for my $predecessor ( $dag->predecessors($task) ) { my $state = $nodes{$predecessor}{state}; die "FATAL: $task.$predecessor: failed\n" if $state == FAIL; die "FATAL: $task.$predecessor: wrong exiting\n" unless $state == DONE; warn "INFO: $task.$predecessor: success\n"; } } else { warn "INFO: $task is the head, starting this task now\n"; } my $node = $nodes{$task}; warn "INFO: running task [$task]\n"; $node->{state} = RUNNING; $node->{start_time} = time; my $action = $nodes{$task}->{action}; my @params = @{ $nodes{$task}->{params} }; my @predecessors = $dag->predecessors($task); if ( ref $action eq 'CODE' ) { $action->($task, { preds => \@predecessors, params => \@params, }); } else { @$node{ 'stdout', 'stderr', 'exit' } = capture { system $action, @params; }; } $node->{end_time} = time; $node->{state} = !$node->{exit} ? DONE : FAIL; }}sub retrieve_stock { my ( $self, $args ) = @_; my $task = $args->{preds}[0]; my ( $stock, $field ) = @{ $args->{params} }; my $json = decode_json( $nodes{$task}{stdout} ); my @quotes = @{ $json->{query}{results}{quote} }; for my $entry (@quotes) { if ( $entry->{symbol} eq $stock ) { $nodes{$self}{stdout} = $entry->{$field}; $nodes{$self}{exit} = 0; } } $nodes{$self}->{exit} = 1 unless exists $nodes{$self}{stdout};}sub aggregator { my ( $self, $args ) = @_; my %changes = (); for my $task ( @{ $args->{preds} } ) { my $stock = $nodes{$task}{params}[0]; my $change = $nodes{$task}{stdout}; $changes{$stock} = $change; } my @sorted = sort { $changes{$b} <=> $changes{$a} } keys %changes; my $winner = $sorted[0]; $nodes{$self}{stdout} = $winner; warn "OUTPUT: The winner is $winner by change $changes{$winner}\n";} |
정리하며
여러분이 태스크 의존도를 고려해 구현해야 하는 서비스가 있다면 아마 지금까지 소개한 방법과 크게 다르지 않게 구현할 수 있을 것입니다. 좀 더 욕심을 내본다면 다음과 같은 것을 적용해 실제로 사용할 수 있는 프레임워크로 구현해보세요.
- NoFlo UI를 이용해 태스크 생성 및 의존성을 정의하는 프론트 엔드 구현
- 각 태스크를 프로세스나 스레드로 구현해 지속적으로 작동하게 구현.
- ZooKeeper나 Redis 같은 백엔드를 이용해 태스크간의 상태 혹은 결과물을 공유
지금까지 펄로 작성했던 툴과 서비스를 헤아려보면 끝이 없을 정도로 많은 일을 헤쳐왔습니다. 펄이 제공 하는 이득과 혜택을 맘껏 누린 셈인데 뒤돌아 보면 펄 없이는 어떻게 그 많은 일들을 처리했을까 싶어 아찔해하곤 합니다. 주로 펄을 이용해 자동화를 구현해온 제게는 펄이 주는 가능성은 정말로 끝이 없답니다. 덕분에 욕심을 부려 더욱 많은 것을 구현해보려고 추구하게 되더군요. 여러분도 펄과 함께 조금 더 욕심을 부려보면 어떨까요?
Enjoy Perl~!! ;-)
- 크리스마스 달력이란
- 펄 크리스마스 달력 #2010
- 펄 크리스마스 달력 #2011
- 펄 크리스마스 달력 #2012
- Perl Advent Calendar
- Perl 6 Advent Calendar
- Perl Catalyst Advent Calendar
- Perl Dancer Advent Calendar
- Future Advent Calendar
- 일본 Perl Advent Calendar
- 일본 Mojolicious Advent Calendar
- Sysadmin Advent Calendar
- 펄.kr
- 네이버 펄 카페
- IRC #perl-kr 채팅
- 한국펄워크샵 2008



{kind=link}
Artwork by
@namanvara,
Hyungsuk Hong
& Inkyung Park.
Designed by
Hojung Youn
& Keedi Kim.
Articles by
Seoul Perl Mongers.
Edited by
Keedi Kim.
Hosting generously sponsored by
Yuni Kim.
Sponsored by
SILEX.
.-''' __ __
/ \/ \/ \
=-_- |
\. -____- / \
// /|| ''
//| //||
== = == ==