
일곱째 날: Perl로 유니코드(Unicode) 코드 포인트(code point)에 해당하는 글자를 확인해보자.
저자
@studioego - 평범한 자바 개발자입니다. 어릴 때 남들은 영어를 배울 때, 혼자서 한자를 배웠던 사람. 한자(漢字, 汉字, Chinese Character)에 대하여 관심이 많으며, 동아시아 언어 처리에 관심이 많음. 취미로 일본어와 중국어를 열심히 공부하고 있습니다. 유니코드 한자관련 내용에 흥미가 있어 유니코드 컨소시엄의 후원 문자(Adopted Characters)에 후원을 하기도 했습니다. GNOME gucharmap 9.0.2버전부터 한자에 대한 한글표기와 베트남어 표기를 추가(버그질라, 소스 코드)한 오픈소스 기여자(contributer), 자유 소프트웨어 개발자입니다. sungdh86+git at gmail.com
시작하며
이 글은 O’Reilly의 Learning Perl 책의 저자인 brian d foy씨가 운영하는 Learning Perl 6 블로그의 Quick Tip #12: Unicode Helper Apps의 내용을 참고하여 만들었습니다. 저는 문자 특히 한자(漢字/汉字)에 대하여 관심이 많은 사람입니다. 그래서 한자 처리에 대한 내용을 찾다보니 Perl이란 언어에 대하여 관심을 가지게 되었습니다. 저는 리눅스 배포판에 탑재된 GNOME gucharmap, KDE kcharselect와 같은 문자표 프로그램을 좋아합니다.
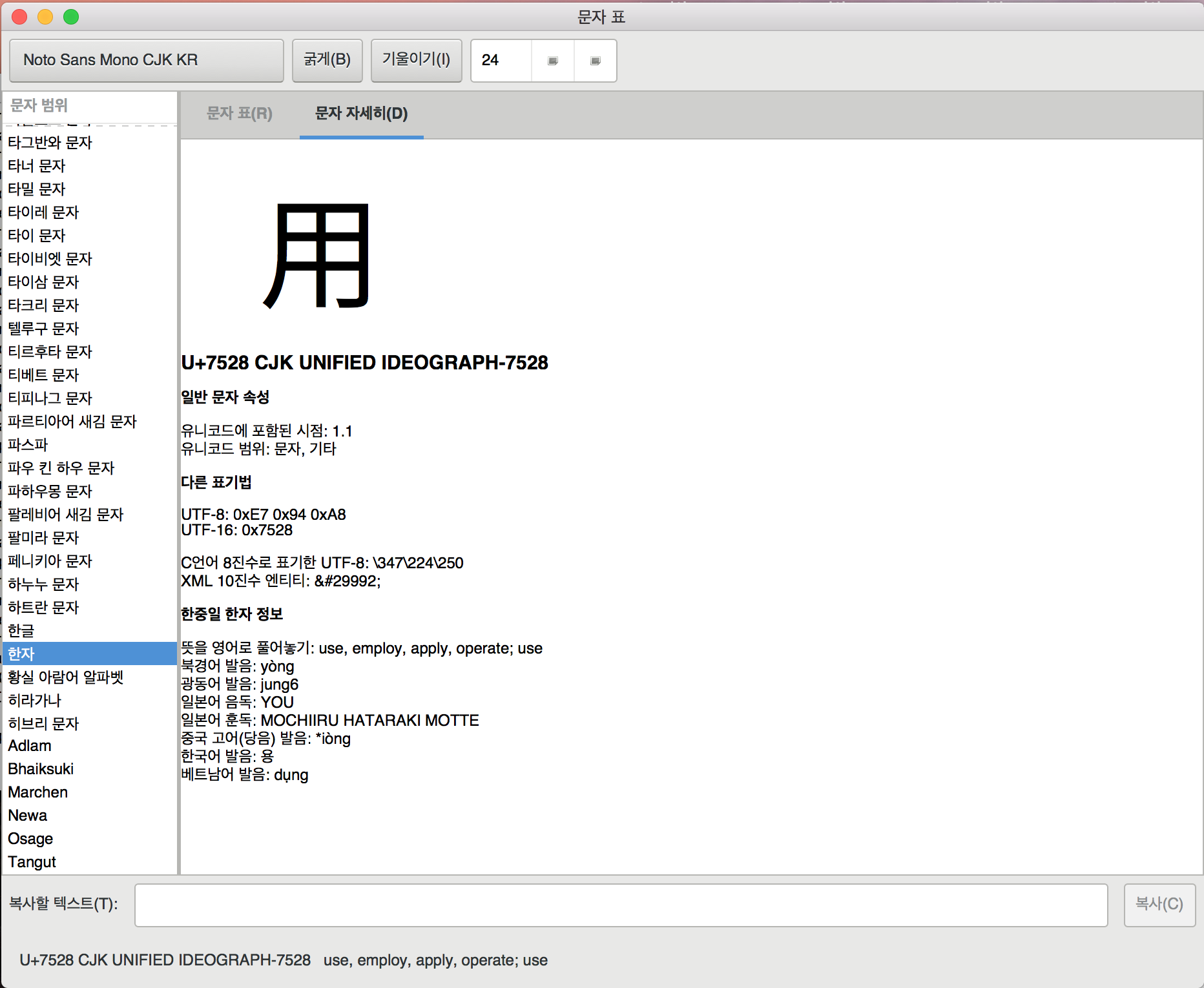
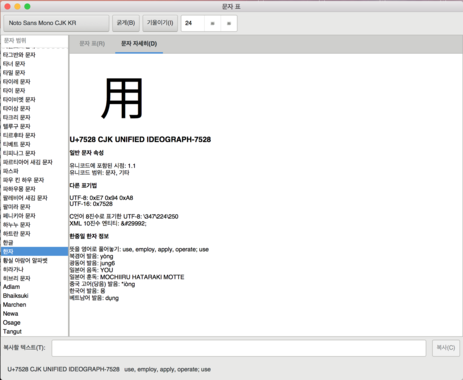 그림 1. GNOME gucharmap(그놈 문자표) (원본)
그림 1. GNOME gucharmap(그놈 문자표) (원본)
그리고 Mac을 사용하고 있다보니 Unicode Checker같은 프로그램도 좋아합니다.
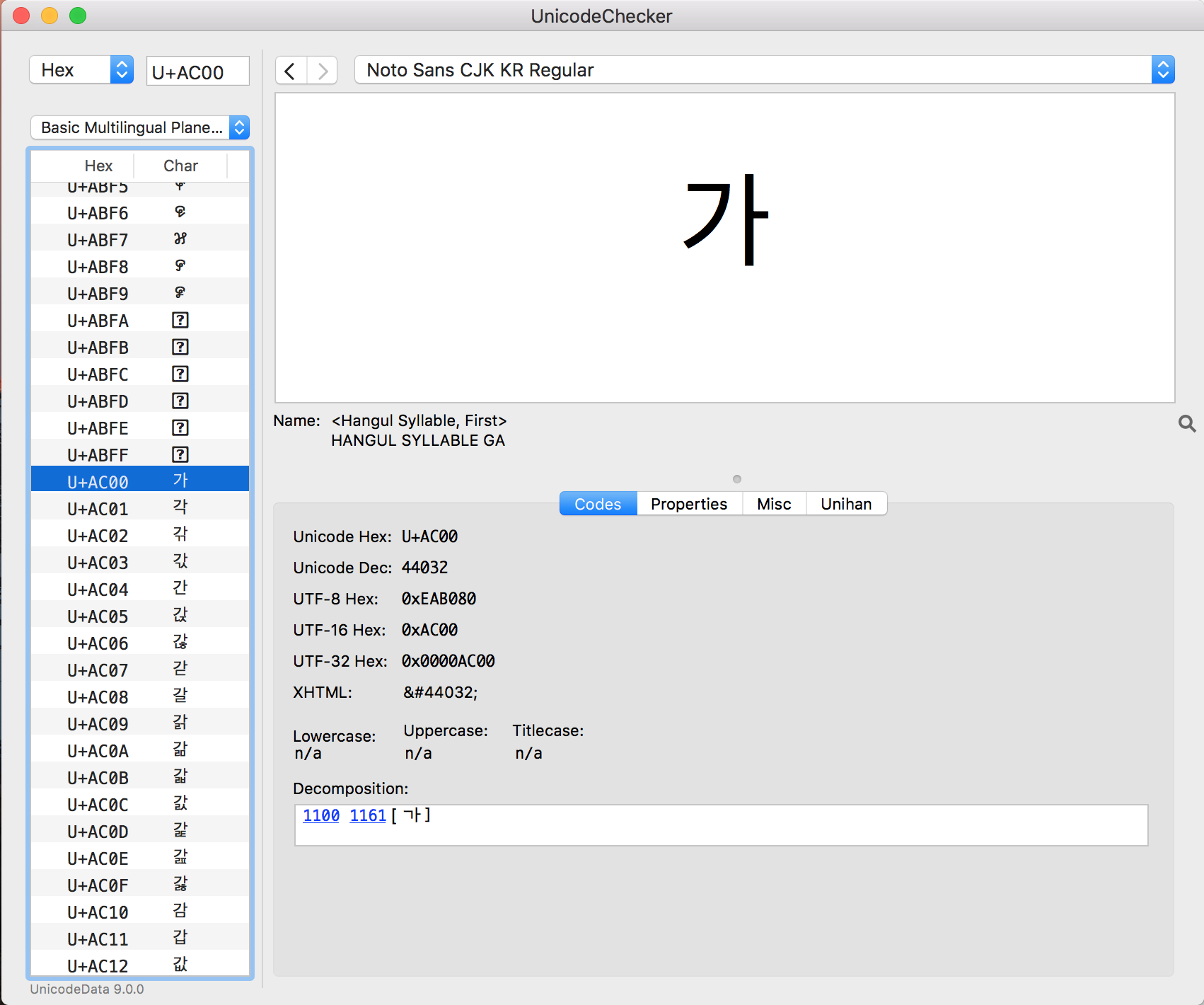
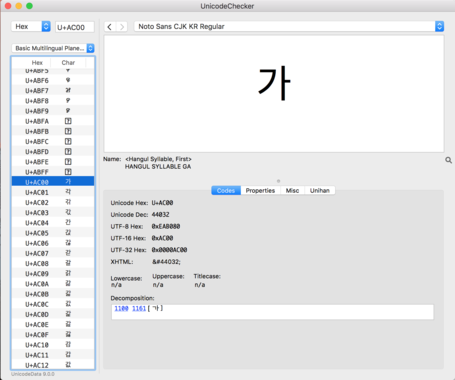 그림 2. 맥용 Unicode Checker (원본)
그림 2. 맥용 Unicode Checker (원본)
GNOME gucharmap이나 Unicode Checker 프로그램을 사용하면 유니코드를 이름으로 검색할 수 있고, 코드 포인트로 검색할 수 있으며, 문자를 붙여놓을 수 있습니다. 문자표의 기능에 대하여 관심이 많다보니, 2016년 11월에 GNOME 문자표(gucharmap) 9.0.2버전에 C언어와 Perl코드로 한자(漢字/汉字)의 한국어 한글 표기와 베트남어 표기 기능을 추가(버그질라, 소스 코드)했습니다. GNOME gucharmap이나 Unicode Checker 프로그램으로 알아낸 16진수로 구성된 코드 포인트를 이용해 Perl로 문자를 표시해볼까요?
준비물
Perl 6를 설치합니다. 그리고 Perl 5도 있으면 Perl 6와 어떤 차이가 있는지 비교할 수 있습니다.
유니코드와 코드 포인트
유니코드(Unicode)는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이며, 유니코드 협회(Unicode Consortium)에서 제정을 하고 있습니다. 현재의 유니코드는 지구상에서 통용되는 대부분의 문자들을 담고 있으며, 악보기호, 이모지(Emoji, 絵文字) 및 특수문자, 등을 담고 있습니다. 유니코드는 1991년 10월에 최초 버전인 1.0.0이 발표되었으며, 약 5년이 지난 1996년 7월에 유니코드 2.0.0에 한글 11,172자가 모두 포함되었습니다. 현재 버전은 2016년 6월 21일 제정된 9.0.0입니다.
유니코드 문자의 경우는 문자의 코드값를 표기할 때 코드 포인트(code point)를 사용하며, U+[16진수 숫자]로 표시합니다.
예를 들어 A의 유니코드 값은 U+0041로 표기 하며 가’의 유니코드 값은 U+AC00로 표기합니다.
유니코드는 논리적으로 평면(plane)이란 개념을 이용하여 구획을 나눕니다.
이 구획은 BMP(다국어 기본 평면), SMP(다국어 보충 평면),
SIP(상형 문자 보충 평면), SSP(특수 목적 보충 평면),
PUA(사용자 정의 영역)등이 정의되어 있습니다.
여러 한자를 다루는 관련 사이트에서는 한자에 해당하는 유니코드(Unicode)의 코드 포인트(code point)로 한자를 표현합니다.
예를 들면 유니코드 韓의 코드 포인트는 U+97D3입니다.
한자의 자형(字形)을 모은 GlyphWiki(글리프위키)의 경우,
한자에 해당하는 코드 포인트 값을 이용하여 중국어 번체, 간체, 일본어, 한국어, 베트남어의 한자 자형을 보여주고 있습니다
韓을 글리프위키 URL에서는 u97d3으로 표기합니다.
그리고 중국에서 만든 한자 사전인 漢典의 경우도 한자에 해당하는 코드 포인트 값을 이용하여 한자의 뜻과 발음, 부수등을 표기하고 있습니다.
韓을 zdic URL에서는 97D3으로 표기합니다.
유니코드 컨소시엄(Unicode Consortium)도 한자에 대한 코드 포인트로 한자에 대한 정보를 보여줍니다.
韓을 유니코드 컨소시엄 URL에서는 97D3으로 표기합니다.
한국학자료센터의 고문서 서체 용례 사전도 코드 포인트를 이용하여 한자에 대한 정보를 보여줍니다.
韓을 한국학자료센터 URL에서는 97D3으로 표기합니다.
코드 포인트로 유니코드를 출력해보자!
이제 Perl 6로 GNOME gucharmap이나 Unicode Checker같은 나만의 프로그램을 작성할 수 있습니다. 코드 포인트를 받아서 문자를 표시하는 방법은 다음과 같습니다. 이 때 터미널 인코딩은 UTF-8로 설정했다고 가정합니다.
1 2 3 | $ perl6 -e 'for @*ARGS { say chr(:16($_)) }' 97D3 570B韓國 |
:16()은 문자열 인수를 16진수로 해석합니다.
2진수 부터 36진수 사이의 진법의 문자열을 :[숫자]()로 붙여서 변환 할 수 있습니다.
Perl 5 에서는 다음과 같이 코드 포인트를 받아서 문자를 표시할 수 있습니다. 이 때 터미널 인코딩은 UTF-8로 설정했다고 가정합니다.
1 2 3 | $ perl -le 'use open ":std", ":encoding(UTF-8)"; foreach $argnum (0 .. $#ARGV) { print chr(hex($ARGV[$argnum])) }' 97D3 5703韓國 |
16진수를 해석하는 hex()함수를 명시적으로 사용한 후에 문자열을 표시함을 알 수 있습니다.
방금 사용한 두 명령을 쉘에서 별칭으로 지정하면 일일이 번거롭게 키보드를 입력하는 수고를 줄이고 간단하게 사용할 수 있겠죠? :)
1 2 | alias p6u2char='perl6 -e "for @*ARGS { say chr(:16(\$_)) }"'alias p5u2char='perl -le 'use open ":std", ":encoding(UTF-8)"; foreach $argnum (0 .. $#ARGV) { print chr(hex($ARGV[$argnum])) }' |
정리하며
Perl 6가 새로 나오는 것을 보면서 Perl 5와 Perl 6의 차이에 대하여 확인하다보니
Learning Perl 6 블로그의 Quick Tip #12: Unicode Helper Apps이 눈에 띄더군요.
글을 읽고 정리하며 유니코드 개념과 코드 포인트개념을 정리하게 되었습니다.
Perl 6에서는 Perl 5와 다르게 2진수 부터 36진수 사이의 진법의 문자열 인수를 :[진법 숫자]()로 붙여서 변환 할 수 있습니다.
Perl 6는 Perl 5와 다르게 문자열 타입에 대하여 기본으로 유니코드(UTF-8 인코딩)를 지원하기 때문에
유니코드를 사용한다고 지정을 하지 않아도 쓸 수 있습니다.
그래서 명시적으로 UTF-8인코딩을 표시하지 않아도 그대로 사용 할 수 있는 것입니다.
아직까지 Perl 5, Perl 6의 차이점에 대하여 완전하게 숙지를 하지 않았지만,
Perl 6가 UTF-8 인코딩을 기본 지원하는 것을 보니, 유니코드로 언어를 처리하는 것이 편해짐을 느낍니다.
문자 사전을 만들게 된다면 문자에 할당된 코드 포인트를 이용하여 만들면 쉽게 정리할 수 있을 것 같네요.
뱀다리
Perl의 강력한 문자 처리 기능을 이용한 프로그램 및 사이트를 몇가지 소개합니다. 그 중 하나는 기사에서도 언급한 GNOME gucharmap (GNOME 문자표) 프로그램입니다. GNOME gucharmap의 한자 자료는 유니코드 컨소시엄(Unicode Consortium)에서 공개한 문자 자료(Unihan database)를 Perl로 처리를 한후, 문자표 화면에 내용을 공개하고 있습니다. 다른 하나는 일본의 언어관련 연구자들이 만든 CHISE(CHaracter Information Service Environment) Project에서 구현한 Perl을 이용한 한자 데이터베이스 모듈이 있습니다. 마지막 자료는 대만의 MoeDict(萌典)입니다.
 그림 3. MoeDict (원본)
그림 3. MoeDict (원본)
대만(중화민국) 행정원의 무임소정무위원(장관급)으로 발탁이 된 천재 해커, 오드리 탕(Audrey Tang, 唐鳳)이 활동하는 대만의 유명한 시빅 해커그룹 g0v零時政府에서 만든 한자 사전 MoeDict(萌典)의 경우, 중화민국 교육부(Ministry Of Education, Republic of China[Taiwan], 中華民國 教育部) 사이트에 공개된 사전자료를 Perl을 이용하여 처리 후 홈페이지 및 안드로이드 앱, 아이폰 앱을 만들어서 공개했습니다. GitHub에 Perl로 구현된 한자 처리 관련 저장소도 존재합니다. 다음은 MoeDict 관련 링크입니다.
- MoeDict 홈페이지
- MoeDict 안드로이드 앱
- MoeDict iOS 앱
- MoeDict Twitter
- MoeDict Facebook
- MoeDict GitHub
- Static API serving for moedict
- Perl로 구현된 한자 처리 관련 저장소
- MoeDict - A dictionary including all the languages that Taiwan people speaks.
- MoeDict 전자책
참고자료
- Learning Perl 6 블로그의 Quick Tip #12: Unicode Helper Apps
- GNOME gucharmap
- KDE kcharselect
- Unicode Checker
- Unicode Consortium
- Unicode 9.0 전체 코드 차트
- Unicode Unihan Database
- Unicode Unihan Lookup
- Announcing The Unicode® Standard, Version 9.0
- 한글 인코딩의 이해 2편: 유니코드와 Java를 이용한 한글 처리
- Perl 6 Advent Calendar 2013 Day 15 - Numbers and ways of writing them
용어 정리
- 용어 정리 - 출처: Ken Lunde, CJKV Information Processing, 2nd Edition
- Moe - Ministry of Education. Written 教育部(jiàoyùbù) in Chinese, 文部省(monbushō) in Japanese, and 교육부/教育部(gyoyukbu) in Korean.
- Moe - Ministry of Education의 약칭. 중국어로
教育部로 쓰고jiàoyùbù로 발음한다. 일본어로文部省로 쓰고monbushō로 발음한다. 한국어로는교육부로 쓰고 한자는教育部이며gyoyukbu로 발음한다.
- 크리스마스 달력이란
- 펄 크리스마스 달력 #2010
- 펄 크리스마스 달력 #2011
- 펄 크리스마스 달력 #2012
- 펄 크리스마스 달력 #2013
- 펄 크리스마스 달력 #2014
- 펄 크리스마스 달력 #2015
- Perl Advent Calendar
- Perl 6 Advent Calendar
- Perl Catalyst Advent Calendar
- Perl Dancer Advent Calendar
- Future Advent Calendar
- 일본 Perl 입학식 Advent Calendar
- 일본 Perl 5 Advent Calendar
- 일본 Perl 6 Advent Calendar
- 일본 Mojolicious Advent Calendar
- Sysadmin Advent Calendar
- Web Design & Devlopment Advent Calendar
- 한국 루비 크리스마스 달력
- 이상한 모임 크리스마스 달력
- 펄.kr
- 네이버 펄 카페
- IRC #perl-kr 채팅
- 한국펄워크샵 2012



{kind=link}
{kind=link}
{kind=link}
X-mas tree
& Llama
ASCII Art by ASCII Art Farts.
Computer ASCII Art by Chris.com.
Cup ASCII Art by ascii.co.uk.
Candle ASCII Art by heartnsoul.com.
Font ASCII Art by ASCII Art Farts.
Text ASCII Art by patorjk.com.
Artwork by
Inkyung Park
& Keedi Kim.
Designed by
Hojung Youn
& Keedi Kim.
Articles by
Seoul Perl Mongers.
Edited by
Keedi Kim.
Hosting sponsored by
SILEX.
Sponsored by
SILEX.
.-''' __ __
/ \/ \/ \
=-_- |
\. -____- / \
// /|| ''
//| //||
== = == ==