다섯째 날: NCBI PubMed와 Perl
저자
@ascendox - 서울시 중구를 지역 기반으로 하는 유전학 전공자. 현재 동국대학교 식물생명공학과 박사 과정으로 분자유전학실험실 유전육종학을 전공하고 있다. 출중한 외모로 인해 중구 얼짱이라는 별칭을 획득. @keedi와 기고 여부를 걸고 다트 내기를 했으나 현실은 기고. 프로필
시작하며
NCBI는 National Center for Biotechnology Information의 약자로 생명 과학 및 의학 관련 학술 포탈 사이트(그림 1)입니다. NCBI는 미국 보건성 산하의 국립 의학 도서관의 운영 분야중 하나로, 생명정보학 전담부서로 컴퓨터를 이용하여 DB를 구축하고 분석도구를 개발하는 것이 주요 임무입니다. 흔히 BLAST로 알려져 있는 이 사이트는 의학 생명 과학 논문 인덱스 데이터 베이스와 유전체 서열 데이터베이스 등 각종 생명 공학 정보들을 담고 있으며 이와 관련있는 분석도구를 보유하고 있습니다.
 그림 1. NCBI 홈페이지 (원본)
그림 1. NCBI 홈페이지 (원본)
또한 생물학적으로 중요한 분자의 구조와 기능을 분석하기 위한 컴퓨터 정보 처리 기술 연구와 수학적, 전산학적 방법을 사용한 생물학 및 의학적 문제의 분자 수준에서의 연구, 분자생물학, 생화학, 유전학에 대한 지식을 저장, 분석하기 위한 자동화 시스템 개발, DB와 S/W 개발, 생명공학 기술 정보 수집, 연구소, 학회, 산업체, 정부 기관 등과의 협력, 과학적 정보교환 강화, 전산생물학의 기초 및 응용 연구 훈련 지원, 다양한 데이터베이스와 소프트웨어의 사용 지원, 데이터베이스 데이터 축적 및 교환, 생물학적 명명법의 표준 개발 등의 활동을 수행하고 있습니다. 나열한 이 모든 정보는 Entrez라는 포탈 검색 엔진을 이용해 검색할 수 있습니다.
대학원생의 삶이란?
흔히 노예... 아니 대학원생의 삶을 살다보면 "내일 까지 뭐 해놔~"와 같은 지극히 일상적인 상황에 직면하게 됩니다. 다음은 한국에서 평범한 대학원생이 직면(당)할 수도 있는 아름다운 상황의 예입니다.
상황 하나.
교수님께서 내일까지 특정 키워드에 대한 논문을 찾아 놓으라고 합니다. 하지만 이럴 경우는 짬밥에 따라 차이가 있지만 보통 거인의 어깨에서 불편한 검색을 제공하는 구글 검색이나 구글 학술 검색을 사용합니다. 구글 검색이나 구글 학술 검색은 키워드로 검색하기 편리하지만 검색 후 그 링크를 언제 다 일일이 찍어서 초록을 뽑아낼 수 있을까요?
상황 둘.
논문 주제를 선정하려고 합니다. 보통 석사 이상의 경우는 자신이 연구한 분야를 집중적으로 혹은 연계하여 논문 주제 혹은 연구 주제를 선정하는 것이 일반적이지만 그럴 여건이 되지 못하는 경우(저처럼 학식이 부족한 경우?)엔 다른 분들의 논문을 보고 정하는 경우가 대부분입니다. 제목과 키워드로 PubMed와 구글에서 찾다가는 시간은 시간대로 가고, 여자(또는 남자) 친구는 여러분을 떠날 것입니다(네... 떠나갔습니다;;).
자 이제 '언제까지 이렇게 살아야하는가? 무언가 획기적인 방법은 없을까?'와 같은 근원적이고 존재론적인 의문이 생길 것입니다. 사실 이 방법을 고수하는 한 '해결 방법 따윈 없다!'랄까요? 획기적이기까지는 아니더라도 좀 더 편한 방법을 이용해 논문을 검색하고 정리 할 수 있다면 어떨까요?
자! 이제 Perl이 출동해야 할 때입니다. ;-)
PubMed 검색 결과
NCBI는 E-utility를 제공하고 있습니다. E-utility를 이용하면 NCBI의 검색엔진인 Entrez에서 programmatic access을 사용할 수 있습니다. E-utillity 내의 E-search를 이용해서 결과에 대한 검색한 후, E-fetch를 이용해서 결과를 출력합니다. 이 작업은 NCBI의 모든 데이터베이스에 대해서 처리할 수 있습니다.
검색한 모든 논문의 전체 내용을 일일이 다 읽어보는 것은 시간적으로도 무리입니다. 사실 그렇게 꼼꼼(!)하게 인생을 살고 있지 않기 때문에 주로 초록(abstract)만 읽곤하죠("논문 쓰기의 시작이자 끝은 초록 쓰기"라는 말이 괜히 나온 것은 아닙니다).
하지만 설명한 방식대로 키워드를 넣고 검색을 하면
저자와 날짜, 제목만을 결과로 보여줍니다.
NCBI 홈페이지에서 rice라는 키워드로 검색을 시도한 다음
Entrez 검색 결과에서 PubMed 카테고리를 선택했을 때
결과 화면은 다음과 같습니다.
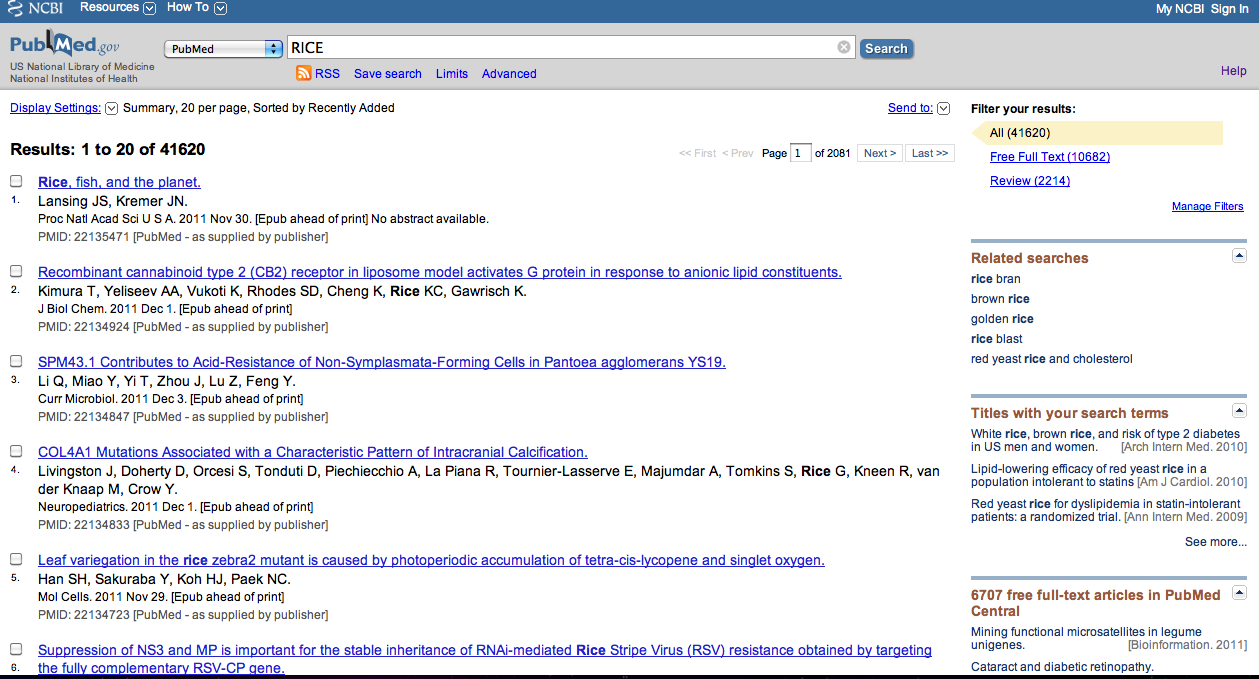 그림 2. NCBI PubMed에서 키워드 rice로 검색한 결과 (원본)
그림 2. NCBI PubMed에서 키워드 rice로 검색한 결과 (원본)
삶의 질을 높이려면?
이렇게 검색한 결과를 클릭해서 초록을 확인하고 정리하면 원하는 바를 이룰수는 있습니다. 하지만 검색 결과가 많을 경우 이렇게 정리하려면 매우 많은 시간이 걸릴 것입니다. 우리의 삶의 질을 높이기 위해 Perl을 이용해서 E-utility의 E-search 기능을 적극적으로 활용해보죠. PubMed에서 science 저널에 2008년에 나온 유방암 논문을 찾는다면 E-utillity의 E-search를 다음처럼 사용합니다.
1 2 3 4 5 6 | # Example:# Get the PubMed IDs (PMIDs) for articles# about breast cancer published in Science in 2008 ?db=pubmed &term=science[journal]+AND+breast+cancer+AND+2008[pdat] |
검색 결과는 XML이지만 E-fetch를 이용하면 원하는 PubMed 결과 자료를 좀 더 보기 쉽게 정리할 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 | Input: List of UIDs (&id); Entrez database (&db); Retrieval type (&rettype); Retrieval mode (&retmode)Output: Formatted data records as specified ?db=<database> &id=<uid_list> &rettype=<retrieval_type> &retmode=<retrieval_mode> |
다음 두 링크는 NCBI에서 제공하는 E-utility의 예제입니다. 역시 바이오 분야에서는 Perl을 쓸때 얼마나 편한지를 다시 한번 확인시켜 주는 듯합니다.
- http://eutils.ncbi.nlm.nih.gov/entrez/query/static/eutils_example.pl
- http://eutils.ncbi.nlm.nih.gov/entrez/query/static/epost.pl
또한 NCBI 는 E-utility의 파이프라인을 Perl로 만들수 있도록 Ebot이란 사이트를 제공합니다. 지금까지 설명한 E-fetch, E-search, XML를 모르더라도 Ebot 사이트를 이용하면 15초 만에 Perl 스크립트를 자동으로 만들어줍니다. 물론 뱀이나 빨간돌 등을 만들어 주는 기능 따윈(!) 없습니다! ;-)
전체 코드
E-search에서 E-fetch를 거쳐서 나온 결과를 재구성하는 전체 Perl 코드는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 | #!/usr/bin/env perluse 5.010;use strict;use warnings;use DateTime;use FindBin qw( $Script );use Getopt::Long;use LWP::Simple;# ---------------------------------------------------------------------------# Parse command line optionsmy %opts = ( 'author' => q{}, 'journal' => q{}, 'min' => 1999, 'max' => DateTime->now->year, 'query' => q{}, 'limit' => 500, 'pdf' => 0, 'tab' => 0, 'help' => 0,);GetOptions( \%opts, 'author|a=s', 'journal|j=s', 'min=i', 'max=i', 'query|q=s', 'limit|l=i', 'pdf!', 'tab!', 'help|h',) or die "Can't parse options\n";die usage() if $opts{help};# ---------------------------------------------------------------------------# Define library for the 'get' function used in the next section.# $db, $query, and $report may be supplied by the user when prompted;# if not answered, default values, will be assigned as shown below.my $db = "Pubmed";my $report = "medline";my $author = ask_user( "Author", $opts{author} );my $journal = ask_user( "journal_name", $opts{journal} );my $query = ask_user( "query", $opts{query} );my $mindate = ask_user( "mindate", $opts{min} );my $maxdate = ask_user( "maxdate", $opts{max} );# ---------------------------------------------------------------------------# $esearch_result containts the result of the ESearch call# the results are displayed parsed into variables# $count, $query_key, and $web_env for later use and then displayed.$author .= "[FAU]" if $author;$journal .= "[TA]" if $journal;my $esearch = make_url( db => $db, retmax => 1, usehistory => 'y', mindate => $mindate, maxdate => $maxdate, datetype => 'pdat', term => $author . $journal . $query,);my $esearch_result = get($esearch);$esearch_result =~ m|<Count>(\d+)</Count>.*<QueryKey>(\d+)</QueryKey>.*<WebEnv>(\S+)</WebEnv>|s;my $count = $1;my $query_key = $2;my $web_env = $3;warn "Count = $count; query_key = $query_key; WebEnv = $web_env\n";if ( $count > $opts{limit} ) { warn "Result count is over $opts{limit}, limitting $opts{limit}\n"; $count = $opts{limit};}# ---------------------------------------------------------------------------# this area defines a loop which will display $retmax citation results from# Efetch each time the the Enter Key is pressed, after a prompt.my %medlines;my $retmax = 20;for ( my $i = 0; $i < $count; $i += $retmax ) { my $efetch = make_url( retmode => 'medline', rettype => $report, retstart => $i, retmax => $retmax, db => $db, query_key => $query_key, WebEnv => $web_env, ); warn "EF_QUERY=$efetch\n"; my $efetch_result = get($efetch); $efetch_result =~ m|<pre>(.+)</pre>|s; $efetch_result = $1; my %medlines_part; %medlines_part = parse_medline($efetch_result); for my $key ( keys %medlines_part ) { $medlines{$key} = $medlines_part{$key}; }}# ---------------------------------------------------------------------------# Print search resultif ( $opts{pdf} ) { for my $pmid ( keys %medlines ) { my $medline = $medlines{$pmid}; my $url_pdf_fetch = make_url( dbfrom => 'pubmed', id => $pmid, retmode => 'ref', cmd => 'prlinks', tool => 'pdfetch', ); printf "[%s] %s\n", $pmid, join( q{}, @{ $medline->{TI} } ); say $url_pdf_fetch; }}elsif ( $opts{tab} ) { for my $pmid ( keys %medlines ) { my $medline = $medlines{$pmid}; my $result = join( "\t", $pmid, join( q{ }, @{ $medline->{TI} } ), join( q{;}, @{ $medline->{AU} } ), join( q{}, @{ $medline->{DP} } ), join( q{ }, @{ $medline->{TA} } ), join( q{ }, @{ $medline->{AB} } ), ); say $result; }}else { for my $pmid ( keys %medlines ) { my $medline = $medlines{$pmid}; printf "[%s] %s\n", $pmid, join( q{}, @{ $medline->{TI} } ); }}# ---------------------------------------------------------------------------# Make URL with parametersub make_url { my ( $base, %params ) = @_; return sprintf( '%s?%s', $base, join('&', map { "$_=$params{$_}" } keys %params), );}# ---------------------------------------------------------------------------# Subroutine to parse medline formatsub parse_medline { my ($raw) = @_; my %records; my @raw = split /[\r\n]/, $raw; my $cur_pmid; my $cur_key; for my $line (@raw) { my $value; if ( $line =~ m{^([A-Z]{2,4}) *- (.+)$} ) { $cur_key = $1; $value = $2; } else { $value = $line; $value =~ s/^\s+//; $value =~ s/\s+$//; } next unless $value; if ( $cur_key eq 'PMID' ) { $cur_pmid = $value; $records{$cur_pmid}->{PMID} = $value; } else { push @{ $records{$cur_pmid}->{$cur_key} }, $value; } } return %records;}# ---------------------------------------------------------------------------# Subroutine to prompt user for variables in the next sectionsub ask_user { my ( $label, $default ) = @_; print STDERR "$label [$default]: "; my $value = <>; chomp $value; return $value ? $value : $default;}# ---------------------------------------------------------------------------# Usage stringsub usage { return <<"HELP"Usage----- $Script <options>Options------- --author|-a Default value of Full Author name of search for --journal|-j Default value of Journal name of search for --min Default value of Min year of search from. Default is 1999 --max Default value of Max year of search from. Default is today --query|-q Default value of keyword of search for --limit|-l Search limit count. Default is 500 --pdf Retrieve pdf info --tab Print tab separated values format --help|h Print help messageExamples-------- $Script -author 'Cheol Seong Jang' -tab $Script -q rice -tabAuthor------ Won Cheol YimHELP} |
다음 명령을 통해 사용법을 확인할 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | $ ./pubmed.pl --helpUsage----- esearch.pl <options>Options------- --author|-a Default value of Full Author name of search for --journal|-j Default value of Journal name of search for --min Default value of Min year of search from. Default is 1999 --max Default value of Max year of search from. Default is today --query|-q Default value of keyword of search for --limit|-l Search limit count. Default is 500 --pdf Retrieve pdf info --tab Print tab separated values format --help|h Print help messageExamples-------- esearch.pl -author 'Cheol Seong Jang' -tab esearch.pl -q rice -tabAuthor------ Oleg Khovayko (PubMed original source) Won Cheol Yim (derived from original source) |
처음에 예를 들었던 쌀을 키워드로 검색하려면 다음처럼 실행합니다.
1 2 3 4 5 6 | $ ./pubmed.pl -q rice[22116964] Assessing Point-of-Care Hemoglobin Measurement: Be Careful We Don't Biaswith Bias.[22130962] Impact of the SRC inhibitor dasatinib on the metastatic phenotype of humanprostate cancer cells.[22121634] Synthesis and characterization of high-purity silica nanosphere from ricehusk.[22056144] Diversity and toxigenicity among members of the Bacillus cereus group.... |
제가 평소 흠모(?)해 마지않는 장철성 교수님(강원대학교 식물자원응용공학과)께서
쓰신 논문의 정보를 탭문자를 구분자로 해서 result 파일에 저장하려면
다음처럼 실행합니다.
1 | $ ./pubmed.pl -a 'Cheol Seong Jang' -tab > result |
두 명의 저자를 검색하고 싶다면 AND 연산자를 사용합니다.
1 | $ ./pubmed.pl -a 'Cheol Seong Jang AND Andrew Paterson' -tab > result |
결과물은 탭 구분자를 이용했기 때문에 놀랍게도 생명 정보학의 친구(?) 엑셀에서 아주 잘 보입니다! 200여줄 남짓한 코드인만큼 코드 분석은 여러분에게 맡기겠습니다. :-)
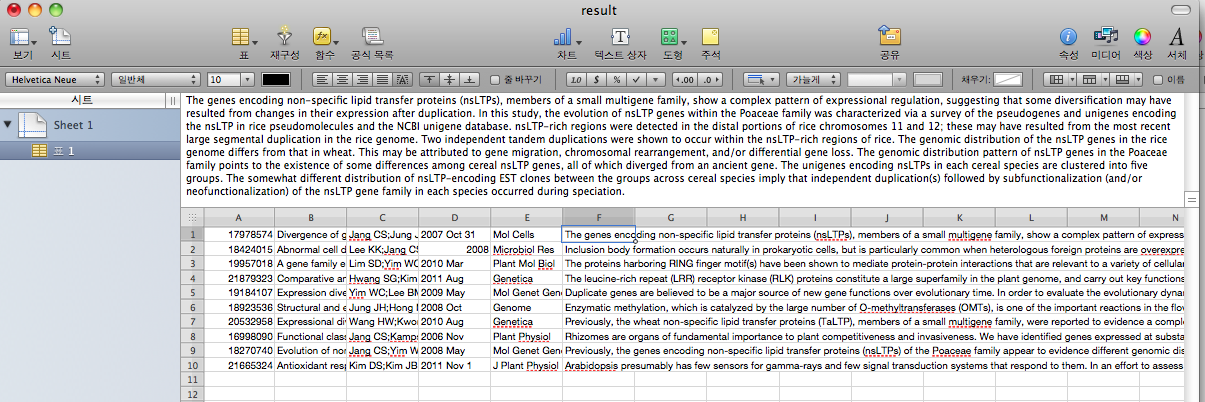 그림 3. 검색 결과를 엑셀에서 열람한 화면(PMID, 제목, 저자, 날짜 저널, 초록) (원본)
그림 3. 검색 결과를 엑셀에서 열람한 화면(PMID, 제목, 저자, 날짜 저널, 초록) (원본)
정리하며
기사에서 설명한 간단한 스크립트가 얼마나 많은 도움을 줄지는 모르겠습니다. 하지만 적어도 앞에서 열거한 상황이라던가, 연구를 위해 급히 많은 양의 초록을 읽어야 한다면 큰 도움이 될 것입니다. 또한 결과값인 연도를 잘 활용하면 특정 키워드의 논문 경향을 분석할 수도 있어 보고서나 RFP를 작성할 때도 유용할 것입니다. E-utility의 경우는 GEO(Gene Expression Omnibus), SRA(Short Read Archive)에서도 사용해 대량의 데이터를 다운 받을 수 있습니다. 실제로 전 GEO의 microarray 데이터 받을때 사용하고 있답니다. ;-)
후기
처음에는 netBLAST를 다루려고 했다가 Ebot과 생명정보학 데이터베이스의 지존인 NCBI에서 사용하는 Perl을 소개할 좋은 기회라서 특별히 NCBI E-utility를 선정했습니다. Seoul.pm 크리스마스 달력에 글을 쓸 수 있는 기회를 주신 @am0c님과 다트 내기에서 놀라운 실력으로 빠져나가지 못하게 한 @keedi님께 감사드리며 미쿡에서 스크립트를 리팩터링 해주신 사랑하는 @yuni_kim, 사랑하는 @aanoaa, 항상 저만 괴롭히는 @JEEN_LEE님께 고마움을 전합니다.
 거침없이 배우는 펄
거침없이 배우는 펄
{kind=link}
Articles by Seoul Perl Mongers
Illustrated by Hyunsu Park, Designed by Hojung Youn, Edited by Hojung Youn & Keedi Kim