
열두번째 날: MySQL을 NoSQL로 사용하기
저자
시작하며 - 일반 서버로 초당 750000 쿼리를 초과한 이야기
대부분의 대규모 웹 응용프로그램들은 MySQL과 memcached를 사용합니다. 그 중 대부분은 TokyoCabinet/Tyrant 같은 NoSQL도 사용하고 있습니다. 몇몇 경우, 사람들은 MySQL을 배제하고, NoSQL과 구분해두었습니다. NoSQL이 MySQL보다 primary key 검색과 같은 단순 접근 패턴에서 훨씬 뛰어나다는 이유로 말입니다. 웹 응용프로그램들로부터 받는 대부분의 쿼리는 단순하기 때문에 이러한 결정이 합리적인 판단으로 보입니다.
다른 대규모 웹 사이트들처럼 DeNA도 몇 년 동안 동일한 문제를 갖고 있었습니다. 그러나 우리는 다른 결과에 도달하였습니다. 지금도 우리는 MySQL만 사용하고 있습니다. 물론 프론트엔드 캐쉬(예를 들어 전처리된 HTML, 조회/미리보기 정보 등)에서는 아직 memcached를 사용하고 있습니다. 그러나 여러 행을 캐쉬하는데에는 사용하지 않습니다. 또한 NoSQL도 사용하고 있지 않습니다. 왜냐고요? 그건 우리가 MySQL에서 다른 NoSQL 제품들보다 더 나은 성능을 얻어낼 수 있었기 때문입니다. 우리는 벤치마크에서 통상 MySQL/InnoDB 5.1 서버와 원격 웹 클라이언트로부터 초당 75만 쿼리를 얻을 수 있었습니다. 제품 환경에서도 놀라운 성능을 얻을 수 있었습니다.
여러분은 저 숫자가 믿기지 않으시겠지만, 이것은 실제 이야기 입니다. 이 긴 블로그 글을 통해 이 경험을 같이 나누길 바랍니다.
SQL은 PK(Primary Key) 검색에 정말 좋을까요?
여러분은 1초당 얼마나 많은 PK 검색을 실행하길 원하십니까? DeNA에 있는 응용프로그램은 사용자 ID로 사용자 정보를 불러오거나, 다이어리 ID로 다이어리 정보를 불러오는 등, 어마어마한 양의 PK 검색을 필요로 합니다. 확실히 memcached 와 NoSQL은 그러한 환경에 가장 잘 맞습니다. 간단하게 멀티스레드로 실행한 "memcached get" 벤치마크를 수행했을 때, 우리는 거의 초당 40만회 이상의 get 동작을 수행할 수 있었습니다. 심지어 memcached 클라이언트들이 원격 서버에 위치했는데도 말입니다. 제가 가장 최신(이 블로그 글이 2010년 10월에 작성되었다는 것에 주의)의 libmemcached와 memcached로 테스트 하였을 때, 4 포트짜리 브로드컴 기가빗 이더넷 카드를 갖은 2.5 GHz 8 코어 네할렘 서버에서 초당 42만 쿼리를 얻을 수 있었습니다.
MySQL은 얼마나 빨리 PK 검색을 실행할 수 있을까요? 벤치마킹 방법은 간단합니다. sysbench, super-smack, mysqlslap 등과 같은 프로그램으로부터 동시다발적인 쿼리들을 실행하면 됩니다.
[matsunobu@host ~]$ mysqlslap --query="select user_name,.. from test.user where user_id=1" \ --number-of-queries=10000000 --concurrency=30 --host=xxx -uroot
여러분은 다음 방법으로 1초당 얼마나 많은 InnoDB 행을 읽었는지 확인할 수 있습니다.
[matsunobu@host ~]$ mysqladmin extended-status -i 1 -r -uroot \ | grep -e "Com_select" ... | Com_select | 107069 | | Com_select | 108873 | | Com_select | 108921 | | Com_select | 109511 | | Com_select | 108084 | | Com_select | 108483 | | Com_select | 108115 | ...
초당 10만개 이상의 쿼리들을 처리하는 것이 나쁜 성능은 아니지만,
memcached에 비하면 무척 느린 것입니다. MySQL은 실제로 무엇을 했을까요?
vmstat 출력을 보면, %user와 %system에 대한 수치는 무척 높습니다.
[matsunobu@host ~]$ vmstat 1 r b swpd free buff cache in cs us sy id wa st 23 0 0 963004 224216 29937708 58242 163470 59 28 12 0 0 24 0 0 963312 224216 29937708 57725 164855 59 28 13 0 0 19 0 0 963232 224216 29937708 58127 164196 60 28 12 0 0 16 0 0 963260 224216 29937708 58021 165275 60 28 12 0 0 20 0 0 963308 224216 29937708 57865 165041 60 28 12 0 0
Oprofile 출력은 어디에서 CPU 자원들을 소비했는지 더 자세히 알려줍니다.
samples % app name symbol name 259130 4.5199 mysqld MYSQLparse(void*) 196841 3.4334 mysqld my_pthread_fastmutex_lock 106439 1.8566 libc-2.5.so _int_malloc 94583 1.6498 bnx2 /bnx2 84550 1.4748 ha_innodb_plugin.so.0.0.0 ut_delay 67945 1.1851 mysqld _ZL20make_join_statistics P4JOINP10TABLE_LISTP4ItemP16st_dynamic_array 63435 1.1065 mysqld JOIN::optimize() 55825 0.9737 vmlinux wakeup_stack_begin 55054 0.9603 mysqld MYSQLlex(void*, void*) 50833 0.8867 libpthread-2.5.so pthread_mutex_trylock 49602 0.8652 ha_innodb_plugin.so.0.0.0 row_search_for_mysql 47518 0.8288 libc-2.5.so memcpy 46957 0.8190 vmlinux .text.elf_core_dump 46499 0.8111 libc-2.5.so malloc
MYSQLparse()와 MYSQLlex()는 SQL 분석 부분에서 호출합니다.
make_join_statistics()와 JOIN::optimize()는 쿼리 최적화 부분에서 호출합니다.
이것들은 SQL의 오버헤드입니다.
이것은 명백히 대부분의 SQL 레이어가 원인이 되어 성능을 떨어뜨리는 것이지,
Inno DB(스토리지) 레이어에 의하여 성능이 떨어지는 것은 아닙니다.
MySQL은 아래의 memcached/NoSQL이 필요로 하지 않는, 더 많은 것들을 할 수 있습니다.
- SQL 명령문 분석(파싱)
- 테이블 열기, 검색하기
- SQL 실행 계획 만들기
- 테이블 언락 및 닫기
MySQL 또한 수많은 동시 제어를 할 수 있습니다.
예를 들어, 네트워크 패킷들을 송수신 할 때, 엄청난 횟수의 fcntl() 함수를 호출합니다.
LOCK_open, LOCK_thread_count과 같은 전역 뮤텍스를 아주 빈번하게 생성하고 해제합니다.
my_pthread_fastmutex_lock()이 Oprofile에서 두 번째로 %output과 %system을 적지 않게 쓰고 있는 이유입니다.
MySQL 개발팀과 외부 커뮤니티 모두 동시성 이슈에 대해 알고 있습니다.
어떤 이슈들은 이미 5.5 버전에서 해결되었습니다.
저는 이미 많은 문제점들이 고쳐졌다는 것에 대해 무척 기쁘게 생각합니다.
그러나 %user가 60%에 육박한다는 점 또한 무척 중요합니다.
뮤텍스 경쟁은 결과적으로 %user 증가가 아닌 %system 증가를 야기합니다.
심지어 MySQL 내부의 모든 뮤텍스 문제들이 고쳐졌다 하더라도, 초당 30만 쿼리를 기대할 수 없습니다.
여러분은 아마도 HANDLER 명령문에 대하여 들은 적이 있을 것입니다.
불행하게도 HANDLER 명령문은 출력 향상에 많은 도움이 되지는 않습니다.
왜냐하면 쿼리를 분석하고, 테이블을 여닫는 일이 아직까진 필요하기 때문입니다.
메모리 기반 작업에서 CPU 효율성은 중요합니다.
만약 메모리 용량에 맞는 활성화된 작은 데이터가 있다면, SQL 오버헤드는 상대적으로 무시할 수 있습니다. 그 이유는 디스크 I/O 비용이 훨씬 높기 때문입니다. 이 경우, 우리는 SQL 비용에 대해 크게 신경 쓸 필요가 없는 것입니다. 그러나 불타고 있는 우리의 몇몇 MySQL 서버들은, 거의 모든 데이터가 메모리 안에 있으며, 완벽하게 CPU와 관련이 있습니다. 프로파일링 결과는 위에 제가 쓴 내용과 동일했습니다.
"SQL 레이어가 대부분의 리소스를 소비한다."
우리는 수많은 Primary key 검색(예를 들어, SELECT x FROM t where id=?)이나 제한된 범위 검색 수행이 필요했습니다.
심지어 쿼리들의 70~80%는 단순히 같은 테이블에서 PK 검색을 하는 것이었습니다.
(차이점은 단순히 WHERE 값이 다를 뿐이었습니다.)
MySQL은 매 쿼리마다 분석하고/열고/닫고/잠궈야 했으며,
그것은 우리에게 효율적으로 보이지 않았습니다.
NDBAPI에 관하여 들어보셨습니까?
MySQL에서 SQL 레이어 전체의 CPU 자원/경쟁을 감소시키는 좋은 솔루션이 있을까요? 만약 여러분이 MySQL 클러스터를 사용하고 있다면, NDBAPI는 좋은 솔루션이 될 수 있을 것입니다. 제가 MySQL/Sun/Oracle에서 컨설턴트로 일했을 때, SQL Node + NDB 성능에 대해 실망하는 많은 고객들을 보았습니다. 그리고 NDBAPI 클라이언트를 작성하는 것으로 몇 배나 더 좋은 성능을 얻고나서야 좋아했습니다. 여러분은 NDBAPI와 SQL을 MySQL 클러스터에서 사용할 수 있습니다. 빈번한 접근 패턴에는 NDBAPI를 사용하고, ad-hoc이나 빈번하지 않은 쿼리 패턴에 대해서는 SQL + MySQL + NDB를 사용하는 것을 추천합니다.
이것이 우리가 원하던 것이었습니다. 우리는 더 빠른 접근 API들을 원하였지만, ad-hoc이나 복잡한 쿼리들에 대해서는 SQL도 사용하기를 원하였습니다. 그러나 DeNA는 다른 웹 서비스들과 같이, InnoDB를 사용하고 있습니다. NDB로 전환하려는 시도는 간단하지 않았습니다. Embedded InnoDB는 SQL이나 네트워크 인터페이스를 모두 지원하지 않았기 때문에 우리에겐 해당사항이 없었습니다.
"HandlerSocket 플러그인" 개발하기 - NoSQL 프로토콜로 말하는 MySQL 플러그인
우리는 MySQL 안에 NoSQL 네트워크 서버를 구현하는 것이 가장 좋은 접근 방법이라고 생각하였습니다. 즉, MySQL 플러그인 (데몬 플러그인)으로서 특정 포트로부터 수신을 하고, NoSQL 프로토콜/API를 수용하고, MySQL 내부 스토리지 API를 사용하여 직접적으로 InnoDB에 접근하는 네트워크 서버를 작성하는 것입니다. 이 접근은 NDBAPI와 동일하지만, 이것은 InnoDB와 통신할 수 있습니다. 이 개념은 초기에 작년 Cybozu Labs에서 Kazuho Oku가 처음 고안하고, 시험해봤던 개념입니다. 우리는 memcached 프로토콜로 통신하는 MyCached를 제작했습니다. 저의 대학에선 Akira Higuchi가 다른 플러그인인 HandlerSocket을 만들었습니다. 아래의 그림은 HandlerSocket이 무엇을 하는지 보여주는 그림입니다.
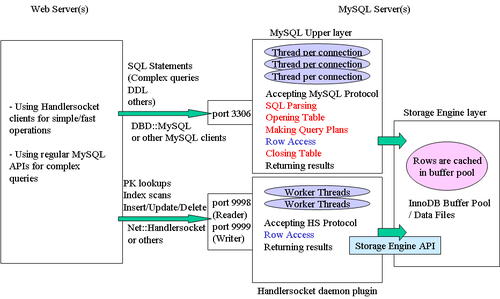 그림 1. HandlerSocket이란 무엇인가? (확대, 원본)
그림 1. HandlerSocket이란 무엇인가? (확대, 원본)
{kind=link}
{kind=link}
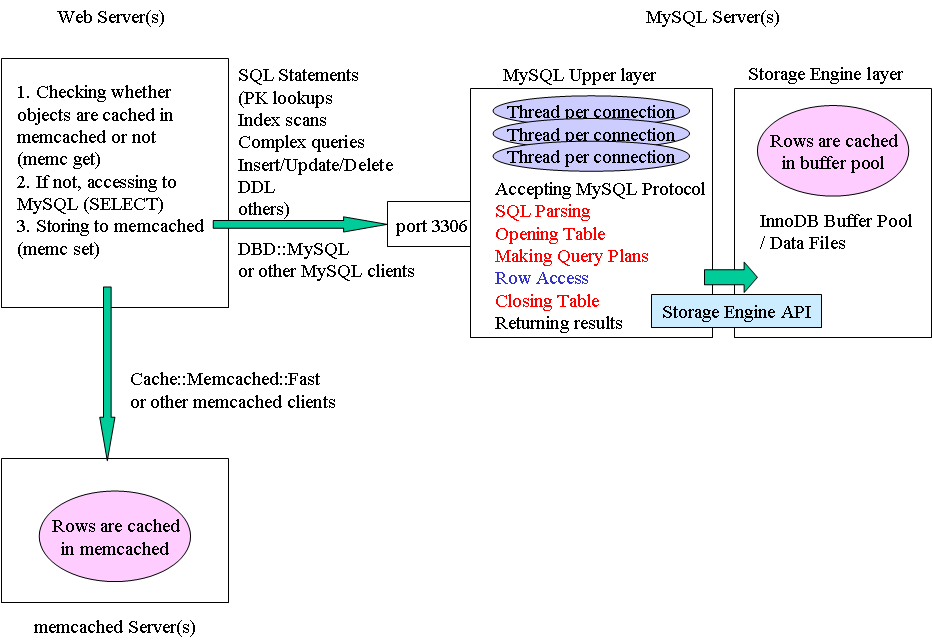
HandlerSocket은 NoSQL과 같이 MySQL을 사용할 수 있는 MySQL 데몬 플러그인입니다. HandlerSocket의 가장 큰 목적은 SQL 관련 오버헤드 없이 InnoDB 와 같은 저장소 엔진과 통신하는 것입니다. 물론 MySQL 테이블에 접근하기 위해 HandlerSocket은 테이블을 여닫을 필요가 있습니다. 그러나 HandlerSocket은 매번 테이블을 여닫지 않습니다. 재사용을 위해 테이블을 열어둔 상태로 유지합니다. 테이블을 여닫는 것은 비용이 아주 비싸고, 심각한 mutex 경쟁을 야기하기 때문에 성능을 개선하는 데에는 아주 도움이 되었습니다. 물론 HandlerSocket은 트래픽이 적을 때에나 여러 상황에서 테이블을 닫기 때문에 관리자 명령어(DDL)를 영원히 막지는 않습니다. MySQL + memcached를 사용하는 것과 무엇이 다르냐고요? 그림 1과 2를 비교해보시면, 많은 차이점을 아시리라 생각합니다. 그림 2는 전형적인 memcached와 MySQL 사용예를 보여줍니다. memcached는 점진적으로 데이터베이스 기록을 캐쉬하는데에 사용합니다. 이것은 memcached get 동작이 MySQL 안에서 메모리/디스크 상의 PK 검색을 하는 것보다 더 빠르다는 것이 주요 이유입니다. 만약 HandlerSocket이 memcached만큼이나 빠르게 레코드들을 불러올 수 있다면, 레코드들을 기록하는데에 memcached를 사용할 필요가 없습니다.
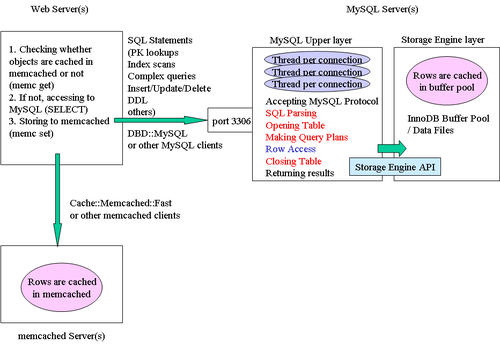 그림 2. MySQL + memcached 에 대한 공통 구조 패턴 (확대, 원본)
그림 2. MySQL + memcached 에 대한 공통 구조 패턴 (확대, 원본)
{kind=link}
{kind=link}
HandlerSocket 사용하기
예를들어, 여기 user 테이블이 있고,
user_id를 이용하여 사용자 정보를 불러올 필요가 있다고 가정해봅시다.
CREATE TABLE user ( user_id INT UNSIGNED PRIMARY KEY, user_name VARCHAR(50), user_email VARCHAR(255), created DATETIME ) ENGINE=InnoDB;
MySQL에서 사용자 정보를 불러들이는 것은 물론 SELECT 명령문으로 가능합니다.
mysql> SELECT user_name, user_email, created FROM user WHERE user_id=101; +---------------+-----------------------+---------------------+ | user_name | user_email | created | +---------------+-----------------------+---------------------+ | Yukari Takeba | [email protected] | 2010-02-03 11:22:33 | +---------------+-----------------------+---------------------+ 1 row in set (0.00 sec)
우리가 위의 작업을 HandlerSocket으로 어떻게 똑같이 할 수 있는지 봅시다.
HandlerSocket 설치하기
설치 단계에 대해서는 여기에 설명해두었습니다. 대강의 기본 단계는 다음과 같습니다.
- HandlerSocket을 다운로드 받습니다.
- HandlerSocket을 (클라이언트와 서버 코드 모두) 빌드합니다.
./configure --with-mysql-source=... --with-mysql-bindir=... ; make; make install - MySQL에서 Handlersocket을 설치합니다.
mysql> INSTALL PLUGIN handlersocket soname 'handlersocket.so';
HandlerSocket이 MySQL 플러그인으로 등록된 이후부터, 여러분은 InnoDB 플러그인, Q4M, Spider 등 다른 플러그인들과 같이 사용할 수 있습니다. 즉, 여러분이 MySQL 소스코드를 직접 수정할 필요가 없습니다. MySQL 버전은 5.1 이후이면 됩니다. 여러분은 HandlerSocket을 빌드하기 위해 MySQL 소스코드와 바이너리 모두 필요합니다.
HandlerSocket 클라이언트 코드 작성하기
우리는 C++와 Perl 클라이언트 라이브러리를 제공합니다. 여기 PK 검색으로 한 행을 불러오는 간단한 Perl 코드가 있습니다.
#!/usr/bin/perl
use strict;
use warnings;
use Net::HandlerSocket;
#1. establishing a connection
my $args = { host => 'ip_to_remote_host', port => 9998 };
my $hs = new Net::HandlerSocket($args);
#2. initializing an index so that we can use in main logics.
# MySQL tables will be opened here (if not opened)
my $res = $hs->open_index(0, 'test', 'user', 'PRIMARY',
'user_name,user_email,created');
die $hs->get_error() if $res != 0;
#3. main logic
# fetching rows by id
# execute_single (index id, cond, cond value, max rows, offset)
$res = $hs->execute_single(0, '=', [ '101' ], 1, 0);
die $hs->get_error() if $res->[0] != 0;
shift(@$res);
for (my $row = 0; $row < 1; ++$row) {
my $user_name= $res->[$row + 0];
my $user_email= $res->[$row + 1];
my $created= $res->[$row + 2];
print "$user_name\t$user_email\t$created\n";
}
#4. closing the connection
$hs->close();
위의 코드는 user_name, user_email을 불러들이고 user 테이블로부터 칼럼을 생성하고,
user_id=101 조건으로 검색을 합니다.
따라서 여러분은 위의 SELECT문과 같은 결과를 얻을 것입니다.
[matsunobu@host ~]$ perl sample.pl Yukari Takeba [email protected] 2010-02-03 11:22:33
대부분의 웹 응용프로그램들에서는 가벼운 HandlerSocket 연결들을 확립(established, 영구적인 연결)하도록 유지하여서 많은 요청을 주요 로직(위의 코드에서 #3)상에 집중하는 것이 좋습니다. HandlerSocket 프로토콜은 크기가 작은 텍스트기반 프로토콜입니다. memcached 텍스트 프로토콜과 같이, 텔넷을 이용하여 HandlerSocket을 통한 결과값들을 얻어올 수 있습니다.
[matsunobu@host ~]$ telnet 192.168.1.2 9998 Trying 192.168.1.2... Connected to xxx.dena.jp (192.168.1.2). Escape character is '^]'. P 0 test user PRIMARY user_name,user_email,created 0 1 0 = 1 101 0 3 Yukari Takeba [email protected] 2010-02-03 11:22:33 (P 0 test user PRIMARY 부분과 0 = 1 101 부분은 요청 패킷 부분으로, 각 토큰 영역은 탭으로 구분해야 한다.)
벤치마킹
이제 우리의 벤치마크 결과를 보여줄 수 있는 시간입니다.
저는 위의 사용자 테이블을 사용하고,
멀티스레드를 이용한 원격 클라이언트로부터
얼마나 많은 PK 검색 동작을 어떻게 수행할 수 있는지 테스트했습니다.
모든 사용자 자료 크기는 메모리 크기에 맞았습니다.
(저는 10만개의 데이터를 테스트 했습니다.)
또한 같은 데이터로 memcached를 테스트 하였습니다.
(사용자 데이터를 불러들이기 위해 libmemcached와 memcached_get()을 사용하였습니다.)
SQL 테스트를 통한 MySQL 테스트에서는, 전통적인 SELECT 문으로
SELECT user_name,user_email, created FROM user WHERE user_id=?를 사용하였습니다.
memcached와 HandlerSocket 클라이언트 코드는 C/C++로 작성하였습니다.
모든 클라이언트 프로그램들은 원격 호스트에 두었으며, TCP/IP를 통한 MySQL/memcached에 연결하였습니다.
가장 높은 수치는 다음과 같습니다.
approx qps server CPU util
MySQL via SQL 105,000 %us 60% %sy 28%
memcached 420,000 %us 8% %sy 88%
MySQL via HandlerSocket 750,000 %us 45% %sy 53%
HandlerSocket을 통한 MySQL이 3/4 밖에 안되는 %us를 가지고도,
SQL 구문을 이용한 전통적인 MySQL보다 7.5배나 높은 결과를 얻을 수 있었습니다.
이는 MySQL 내의 SQL 레이어가 무척 비용이 비싸다는 것과 레이어를 우회하는 것이
극적으로 성능을 향상시킨다는 것을 보여줍니다.
또한 memcached는 %system 자원을 더 많이 사용함에도 불구하고,
HandlerSocket이 memcached보다 178% 더 빠르다는 것이 흥미롭습니다.
비록 memcached는 훌륭한 제품이지만, 최적화의 여지가 남아 있습니다.
아래의 내용은 oprofile의 출력물로 HandlerSocket을 이용한 MySQL 테스트 동안에 얻은 내용입니다. CPU 자원들은 네트워크 패킷 핸들링, 행 불러오기 등, 핵심 동작들에 소비되고 있습니다. (bnx2는 네트워크 드라이버 프로그램입니다.)
samples % app name symbol name 984785 5.9118 bnx2 /bnx2 847486 5.0876 ha_innodb_plugin.so.0.0.0 ut_delay 545303 3.2735 ha_innodb_plugin.so.0.0.0 btr_search_guess_on_hash 317570 1.9064 ha_innodb_plugin.so.0.0.0 row_search_for_mysql 298271 1.7906 vmlinux tcp_ack 291739 1.7513 libc-2.5.so vfprintf 264704 1.5891 vmlinux .text.super_90_sync 248546 1.4921 vmlinux blk_recount_segments 244474 1.4676 libc-2.5.so _int_malloc 226738 1.3611 ha_innodb_plugin.so.0.0.0 _ZL14build_template P19row_prebuilt_structP3THDP8st_tablej 206057 1.2370 HandlerSocket.so dena::hstcpsvr_worker::run_one_ep() 183330 1.1006 ha_innodb_plugin.so.0.0.0 mutex_spin_wait 175738 1.0550 HandlerSocket.so dena::dbcontext:: cmd_find_internal(dena::dbcallback_i&, dena::prep_stmt const&, ha_rkey_function, dena::cmd_exec_args const&) 169967 1.0203 ha_innodb_plugin.so.0.0.0 buf_page_get_known_nowait 165337 0.9925 libc-2.5.so memcpy 149611 0.8981 ha_innodb_plugin.so.0.0.0 row_sel_store_mysql_rec 148967 0.8943 vmlinux generic_make_request
HandlerSocket을 통한 MySQL 테스트가 MySQL에서 수행되고, InnoDB를 접근하기 시작하면, SHOW GLOBAL STATUS와 같은 일반 MySQL 명령어로부터 통계값을 얻을 수 있습니다. 75만회 이상의 Innodb_rows_read 를 볼 수 있습니다.
$ mysqladmin extended-status -uroot -i 1 -r | grep "InnoDB_rows_read" ... | Innodb_rows_read | 750192 | | Innodb_rows_read | 751510 | | Innodb_rows_read | 757558 | | Innodb_rows_read | 747060 | | Innodb_rows_read | 748474 | | Innodb_rows_read | 759344 | | Innodb_rows_read | 753081 | | Innodb_rows_read | 754375 | ...
서버에 대한 자세한 사양은 다음과 같습니다.
Detailed specs were as follows.
Model: Dell PowerEdge R710
CPU: Nehalem 8 cores, E5540 @ 2.53GHz
RAM: 32GB (all data fit in the buffer pool)
MySQL Version: 5.1.50 with InnoDB Plugin
memcached/libmemcached version: 1.4.5(memcached), 0.44(libmemcached)
Network: Broadcom NetXtreme II BCM5709 1000Base-T (Onboard, quad-port, using three ports)
memcached와 HandlerSocket 양쪽 모두 네트워크 I/O 대역폭을 모두 소모하였습니다. 단일 포트로 테스트 했을 때는 HandlerSocket을 이용하는 쪽이 초당 26만 쿼리, memcached 상에서는 22만 쿼리에 근접했습니다.
HandlerSocket의 구성요소와 이점
HandlerSocket은 다음과 같은 다양한 구성요소와 이점을 가지고 있습니다. 그것들 중 몇몇은 실제로 우리에게 유용한 것들입니다.
다양한 쿼리 패턴을 지원
HandlerSocket은 PK/unique 검색, non-unique 검색, 범위 스캔, LIMIT, 그리고 INSERT/UPDATE/DELETE를 지원합니다. index를 사용하지 않는 동작들은 지원하지 않습니다. multi_get 동작 (IN(1,2,3..)과 유사한, 단일 네트워크 round-trip을 통한 다중 행들을 불러오기) 또한 지원합니다.
HandlerSocket 플러그인 문서에서 자세한 사항을 확인하십시오.
수많은 동시 접속들을 제어할 수 있음
HandlerSocket 연결은 가볍습니다.
HandlerSocket이 epool()과 worker-thread/thread-pooling 구조를 채용한 이후로,
MySQL 내부 스레드 수가 제한사항이 되었습니다.
(my.cnf 안에서 handlersocket_threads 파라메터로 제어할 수 있습니다.)
따라서 여러분은 수백에서 수십만 네트워크 접속을
안정성을 잃지 않고(너무 많은 메모리를 사용하거나, 뮤텍스 경쟁을 야기하지 않는 등
(버그 #26590, #33948,
#49169와 같은 문제점), 영구적으로 유지할 수 있습니다.
극한의 고성능
이미 설명하였지만, HandlerSocket은 다른 NoSQL 라인업들과 대항할 수 있는 충분히 경쟁할 만한 성능을 얻을 수 있습니다. 실제로 일반 TCP/IP를 통한 원격 클라이언트들을 사용하여, 일반 서버상에서 75만 쿼리 이상을 수행하는 것을 본적이 없습니다. HandlerSocket은 SQL 관련 함수 호출을 없앴을 뿐만 아니라, 네트워크/동시성 문제도 최적화 하였습니다.
더 작은 네트워크 패킷
HandlerSocket 프로토콜은 일반 MySQL 프로토콜보다 아주 단순하고 작습니다. 따라서 전체 네트워크 전송 크기가 무척 작습니다. 제한적인 MySQL 내부 스레드의 수에서도 동작합니다. 위에 이미 설명하였습니다.
클라이언트 요청을 그룹핑 합니다.
HandlerSocket에 수많은 동시 요청이 몰릴 경우, 각 워커 스레드는 가능한 많은 요청을 모으고, 모은 요청을 한 번에 수행하며 결과를 돌려줍니다. 이것은 응답시간을 약간 소모하는 것으로 성능을 비약적으로 개선할 수 있었습니다. 예를 들어, 여러분이 다음과 같은 이익을 얻을 수 있습니다. 원하신다면 이후의 글에서 더 자세히 설명하도록 하겠습니다.
fsync()호출의 수를 줄일 수 있다.- 리플리케이션(복제) 지연을 감속할 수 있다.
중복 캐쉬 복제가 일어나지 않는다.
memcached를 이용하여 MySQL/InnoDB 레코드들을 캐쉬할 때, 레코드들은 memcached와 InnoDB 버퍼 풀 안에 같이 캐쉬되어 있습니다. 그것들은 효율성을 떨어뜨립니다. (메모리 공간을 더 많이 차지하게 됩니다.) Handlersocket 플러그인이 InnoDB 저장소 엔진에 접근하고 나서부터, 레코드들은 다른 SQL 명령문들이 재사용할 수 있도록 InnoDB 버퍼 풀에 캐쉬됩니다.
자료 불일치가 없다.
한 장소(내부 InnoDB)에 자료가 저장된 후부터, memcached와 MySQL 사이에서의 자료 일치 확인과 같은 동작은 필요없게 되었습니다.
충돌로부터 안전합니다.
백엔드 저장소가 InnoDB입니다.
이는 트렌젝션을 지원하며, 충돌에 안전합니다.
심지어 innodb-flush-log-at-trx-commit이 1이 아니더라도,
서버 충돌로부터 1초 미만의 데이터만 잃게 됩니다.
mysql 클라이언트로 SQL도 사용할 수 있습니다.
많은 경우, 사람들은 아직도 SQL을 사용하길 원합니다. (예를 들어, 요약 보고서를 생성하기 위해서) 이것이 Embedded InnoDB를 쓸 수 없었던 이유입니다. 대부분의 NoSQL 제품들은 SQL 인터페이스를 지원하지 않습니다. HandlerSocket은 단순히 MySQL에 대한 플러그인입니다. 여러분은 MySQL 클라이언트로부터 SQL 명령문을 전달할 수 있으며, 높은 성능을 필요로 할 때에는 HandlerSocket 프로토콜을 사용할 수도 있습니다.
MySQL로부터의 모든 부가적인 이점
다시 말하지만, HandlerSocket은 MySQL 안에서 수행하며,
예를 들어, SQL, 온라인 백업, 리플리케이션,
Nagios/EnterpriseMonitor에 의한 모니터링 등과 같은
모든 MySQL 동작들을 지원합니다. HandlerSocket 동작은
SHOW GLOBAL STATUS, SHOW ENGINE INNODB STATUS, SHOW PROCESSLIST와 같은
정규 MySQL 명령으로 모니터링 할 수 있습니다.
MySQL을 수정하거나 재설치 할 필요 없음
플러그인이기 때문에 MySQL 커뮤니티나 MySQL 엔터프라이즈 서버 상에서 모두 실행시킬 수 있습니다.
스토리지 엔진으로부터 독립적임
비록 InnoDB Plugin 5.1과 5.5에서만 테스트 하였고 사용하고 있지만, HandlerSocket은 어떤 버전의 스토리지 엔진들과도 통신할 수 있도록 개발하였습니다.
주의점과 한계점
HandlerSocket API를 배울 필요가 있음
사용하기는 쉽지만, 여러분은 HandlerSocket으로 통신하기 위한 프로그램을 작성할 필요가 있습니다. 우리는 C++ API와 Perl binding을 제공합니다.
보안체계가 없습니다.
다른 NoSQL 데이터베이스들처럼, HandlerSocket은 어떤 보안 요소도 제공하지 않습니다. HandlerSocket의 워커 스레드들은 시스템 사용자 권한으로 동작합니다. 따라서 응용프로그램은 HandlerSocket 프로토콜로 모든 테이블에 접근할 수 있습니다. 물론 여러분은 다른 NoSQL 제품들처럼 패킷을 막기 위해 방화벽을 사용할 수 있습니다.
HDD 동작한계에 대한 이점이 없음
HDD I/O 동작한계 안에서, 일반적인 결과로 1-10% CPU 사용율 내에, 데이터베이스 인스턴스는 초당 수천개의 쿼리들을 수행할 수 없습니다. 그러한 경우, SQL 수행 레이어는 병목현상을 일으키지 않습니다. 따라서 HandlerSocket을 사용할 이유가 없습니다. 우리는 서버상에서 모든 데이터를 메모리에 맞게 넣어두고 HandlerSocket을 사용하고 있습니다.
DeNA는 제품에서 HandlerSocket을 사용하는 중입니다.
우리는 이미 HandlerSocket 플러그인을 우리의 제품 환경에서 사용하고 있습니다. 결과는 훌륭합니다. 우리는 많은 memcached와 MySQL 슬레이브 서버들을 줄일 수 있었습니다. 전체 네트워크 트래픽도 감소하였습니다. 우리는 어떤 성능 문제(응답시간이 줄어들거나, 스톨에 걸리는 등)도 보질 못했습니다. 우리는 결과에 아주 만족합니다.
제가 생각하기에 MySQL은 NoSQL/Database 커뮤니티로부터 저평가받고 있는것 같습니다. MySQL은 실제로 다른 대부분의 제품들보다 훨씬 더 많은 역사를 가지고 있으며, 독자적이고 훌륭한 많은 개선점들을 달성해왔습니다. 저는 NDBAPI로부터 MySQL이 NoSQL로서의 강력한 잠재 능력을 가졌다는 것을 압니다. 저장소 엔진 API와 데몬 플러그인 인터페이스는 완벽하게 독자적입니다. 그리고 그것들이 Akira와 DeNA가 HandlerSocket을 개발할 수 있도록 만들어 주었습니다. MySQL의 이전 고용자로서 그리고 MySQL에 대한 오랜 즐거움 때문에, 저는 MySQL이 단순 RDBMS로서만이 아니라, 또 다른 Yet Another NoSQL 라인업이 되는 것을 바랍니다.
HandlerSocket 플러그인은 오픈소스이니, 마음껏 사용하시기 바랍니다. 어떠한 피드백이라도 감사합니다.
옮기며
이 글의 원문은 요시노리 마쯔노부의 블로그 포스트입니다. 역자는 @jachin24입니다.
Articles by
Seoul Perl Mongers,
Artwork by
Yura Lee
Designed by
Yura Lee
& Hojung Youn,
Edited by
Hojung Youn,
JellyPooo
& Keedi Kim.