
스무번째 날: Gearman 사용 사례
저자
@gypark - Perl을 좋아합니다. GyparkWiki의 Perl페이지에서 Perl 관련 문서들을 정리해두고 있습니다.
시작하며
최근에 다수의 압축 파일을 열고 내용을 확인하는 작업을 하게 되었습니다. 순차적으로 파일 하나하나를 처리하다보니 시간이 꽤 걸리길래, 혹시나 하는 생각에 Gearman을 사용해 보았고 생각 이상으로 효과가 좋다는 것을 알 수 있었습니다. 이 기사에서 그 예제 코드와 결과를 공유하고자 합니다.
Gearman에 대하여
Gearman에 관한 상세한 소개는 이미 Seoul.pm 2012년 크리스마스 달력에서 다루고 있습니다.
따라서 이 기사에서는 이런 소개는 생략하고, 작년 기사의 코드를 응용해 작업을 나눠 워커에 분배하고 수행 결과를 보이는데 집중하도록 하겠습니다.
준비물
작년 기사와 마찬가지로 순수 펄로 구현된 Gearman 서버, 워커, 클라이언트를 사용했습니다. 또한 이후에 설명할 실제 작업을 위해서는 몇 가지 모듈이 추가로 필요합니다. 필요한 모듈은 다음과 같습니다.
- CPAN의 Archive::Zip 모듈
- CPAN의 File::Slurp 모듈
- CPAN의 Gearman::Client 모듈
- CPAN의 Gearman::Server 모듈
- CPAN의 Gearman::Worker 모듈
직접 CPAN을 이용해서 설치한다면 다음 명령을 이용해서 모듈을 설치합니다.
$ sudo cpan \ Archive::Zip \ File::Slurp \ Gearman::Client \ Gearman::Server \ Gearman::Worker
사용자 계정으로 모듈을 설치하는 방법을 정확하게 알고 있거나 perlbrew를 이용해서 자신만의 Perl을 사용하고 있다면 다음 명령을 이용해서 모듈을 설치합니다.
$ cpan \ Archive::Zip \ File::Slurp \ Gearman::Client \ Gearman::Server \ Gearman::Worker
작업 내용
제가 처리해야 할 작업은 다음과 같습니다.
디렉터리 안에 다수의 ZIP 형식의 압축 파일이 있는 상태에서 각 압축 파일을 열고,
LIST.txt 파일을 추출한 후, 그 파일 안에 Perl이라는 문자열이 존재하는지 검사합니다.
이 문자열이 없다면 그 압축 파일에 문제가 있는 것이므로 로그에 따로 기록을 합니다.
일반적인 순차 처리
처음에 작성했던 스크립트입니다. 디렉터리 안의 모든 파일을 대상으로 루프를 돌면서 열고 추출하고 내용을 검사하는 과정을 반복합니다.
#!/usr/bin/env perl
use strict;
use warnings;
local $| = 1;
use Archive::Zip qw( :ERROR_CODES :CONSTANTS );
use File::Slurp qw( read_file );
my $member = 'LIST.txt'; # ZIP 파일 내에서 꺼낼 파일
my $target = 'Perl'; # 꺼낸 파일 안에 들어 있어야 하는 문자열
my $zip = Archive::Zip->new();
open my $fh, '>', 'log_sequential.txt' or die $!; # 로그파일
for my $file ( glob '/Users/gypark/temp/gearman/data/*' ) {
print $fh "[$file]\n";
# 압축 파일을 읽고
die 'read error' unless $zip->read($file) == AZ_OK;
# 특정 파일을 추출한 다음
die 'extract error' unless $zip->extractMemberWithoutPaths($member) == AZ_OK;
# 그 파일 안에 특정한 문자열이 있는지 확인
my $str = read_file($member);
print $fh "ERROR! $file : $str\n" unless $str =~ m|$target|i;
# 추출했던 파일은 삭제
unlink $member or die "unlink:$!";
}
close $fh;
이 스크립트를 실행하면, 검사한 압축 파일의 이름이 로그 파일에 기록됩니다.
[/Users/gypark/temp/gearman/data/00001.zip] [/Users/gypark/temp/gearman/data/00002.zip] [/Users/gypark/temp/gearman/data/00003.zip] ...
기사 작성을 위해 테스트할 때는 디렉터리 아래 ZIP 파일이 2만 개 있었습니다. 그리고 이 스크립트가 수행을 마칠 때까지 약 55초 정도 소요되었습니다. 실제 업무 환경에서 작업했을 때는 압축 파일의 수도 훨씬 더 많았고, 시간도 수 분 걸렸습니다.
Gearman으로 옮기기
이제 2만 개의 파일 목록을 쪼개어서 여러 워커에서 작업할 수 있도록 옮겨보죠.
Gearman 클라이언트
해야할 일을 여러 개의 작은 작업으로 나누어 워커에게 맡기는 클라이언트 코드입니다. 주요 흐름은 작년 기사에서 예제로 나왔던 합계 구하기 코드와 거의 유사합니다. 실제로 문제가 되는 것은 작업을 어떻게 쪼갤 것인가입니다. 처리해야 할 작업이 다수의 파일에 동일한 일을 수행하는 것이므로 2만개의 전체 파일을 1천개씩 나누어서 파일 이름의 목록 스무 개를 워커에 넘겨주는 것으로 쉽게 작업을 분할할 수 있었습니다.
#!/usr/bin/env perl
use strict;
use warnings;
use Gearman::Client;
use Storable qw( freeze thaw );
# 작업 대상 목록을 만든다 (현재 2만개)
my @list = glob '/Users/gypark/temp/gearman/data/*';
# Gearman 클라이언트를 생성하고
my $client = Gearman::Client->new;
$client->job_servers('127.0.0.1:20000');
# 클라이언트가 수행할 작업 집합을 만들고
my $tasks = $client->new_task_set;
# 이 작업 집합에 워커에 맡길 작업을 등록한다.
my $num = 0;
while ( @list ) {
# 눈으로 확인하기 위해 작업마다 일련번호를 붙이자.
$num++;
# 2만개의 파일이름 목록을 1000개씩 뽑아낸다.
my @sublist = splice @list, 0, 1000;
# 작업 등록
my $handle = $tasks->add_task(
# 워커에 넘겨 줄 인자는 Storable::freeze를 써서 직렬화한다.
check => freeze( { num => $num, list => [ @sublist ] } ),
{
# 각 워커가 종료될 때마다
# 화면에 그 사실을 출력하도록 하자.
on_complete => sub {
my $arg = ${ $_[0] };
print "task [$arg] done.\n";
},
},
);
}
$tasks->wait;
Gearman 워커
Gearman 워커는 클라이언트로부터 파일 목록을 넘겨받아 그 목록에 있는 파일을 열고 검사하는 실제 작업을 수행합니다.
따라서 워커가 하는 일은 앞에서 보았던 순차 처리 스크립트의 내용을 고스란히 포함하고 있습니다. 다만 이번에는 여러 워커가 동시에 일을 하기 때문에 추출한 파일이 서로 겹치지 않도록 각 워커가 임시 디렉터리를 만들어서 그 안에서 작업하도록 합니다. 또한 로그 파일도 각 작업마다 따로 만들어서 기록하도록 합니다.
#!/usr/bin/env perl
use strict;
use warnings;
local $| = 1;
use Gearman::Worker;
use Archive::Zip qw( :ERROR_CODES :CONSTANTS );
use Cwd;
use File::Slurp;
use File::Temp qw( tempdir );
use Storable qw( thaw freeze );
my $member = 'LIST.txt'; # ZIP 파일 내에서 꺼낼 파일
my $target = 'Perl'; # 꺼낸 파일 안에 들어 있어야 하는 문자열
# Gearman 클라이언트를 생성하고
my $worker = Gearman::Worker->new;
$worker->job_servers('127.0.0.1:20000');
# check 작업 요청이 왔을 때 check() 서브루틴을 실행하도록 등록
$worker->register_function( check => \&check );
# 야~ 야근이다! ;-)
$worker->work while 1;
# 호출될 서브루틴
sub check {
# 클라이언트는 freeze로 직렬화하여 인자를 넘겨줬다.
# 이 인자는 $_[0]->arg 를 통하여 얻어낼 수 있고,
# 이것을 다시 Storable::thaw()를 써서 원래의 형태로 변환해야 한다.
my $arg = thaw( $_[0]->arg );
# 원래 형태가 해시 레퍼런스였으므로
# 다시 여기서 num과 list를 뽑아내자
my $num = $arg->{num};
my @list = @{ $arg->{list} };
my $zip = Archive::Zip->new;
# 로그 파일 이름에 작업 번호를 붙여서 구분할 수 있게 한다.
my $log = sprintf( "log_gearman_%02d.txt", $num );
open my $fh, '>', $log or die $!;
# 현재 작업 디렉터리를 기억해두고
my $cwd = getcwd;
# 임시 디렉터리를 만들어서 그쪽으로 이동 후 작업한다.
my $dir = tempdir( CLEANUP => 1 );
chdir $dir;
# @list에 나열되어 있는 각 파일에 대해 이전과 동일한 작업을 수행한다.
for my $file (@list) {
print $fh "[$file]\n";
die "read error [$num][$file]" unless $zip->read($file) == AZ_OK;
die "extract error [$num][$file]" unless $zip->extractMemberWithoutPaths($member) == AZ_OK;
my $str = read_file($member);
print $fh "ERROR! $file : $str\n" unless $str =~ m/$target/i;
unlink $member or die "unlink:$!";
}
close $fh;
# 원래 작업 디렉터리로 복귀
chdir $cwd;
rmdir $dir or die "rmdir:$!";
# 방금 수행한 부분 작업의 일련 번호를
# 다시 클라이언트에 알려주자.
return "<$num>";
}
눈여겨 볼 부분은 클라이언트와 워커 사이에 인자를 전달하는 형태입니다. 작년 기사와 마찬가지로 클라이언트에서 워커로 복잡한 자료 구조를 넘겨주기 위해서 Storable 모듈을 사용합니다.
또한 워커의 check() 사용자 함수가 종료할 때는 평범한 문자열을 반환하지만
클라이언트의 on_complete 익명 함수가 이것을 전달받을 때는
그 문자열의 레퍼런스가 인자로 전달됩니다.
따라서 ${ $_[0] }처럼 역참조(dereference)해야 합니다.
평범한 문자열이 아니라 배열이나 해시 등 더 복잡한 자료 구조를
반환하고 싶을 때도 역시 직렬화해야 합니다.
실행
Gearman 서버 실행
여기서는 20000 포트로 통신하기 때문에 서버를 실행할 때도 포트 번호를 지정해줍니다.
$ gearmand -p 20000
Gearman 워커 실행
워커를 몇 대나 띄워야 비용 대비 효과가 제일 클 것인가?는 아마도 상황마다 다를 것 같습니다. 이와 관련해서 작년의 16일자 기사에서는 워커를 관리하는 용도로 쓸 수 있는 Gearman::SlotManager 모듈을 소개하고 있습니다.
지금은 단순하게 터미널에서 수작업으로 띄우도록 합니다.
일단 두 대를 띄우기로 합시다.
쉘에서 실행시킬 때 &를 붙여서 후면 작업(background)으로 실행합니다.
$ perl gearman_worker.pl & [1] 81618 $ perl gearman_worker.pl & [2] 81622
Gearman 클라이언트 실행
서버와 워커가 준비되었으니 이제 실제로 작업 수행을 요청할 클라이언트를 실행합니다.
$ perl gearman_client.pl
클라이언트가 실행되면 워커가 일을 하고 마칠 때마다 결과가 출력됩니다.
task [<2>] done. task [<1>] done. task [<3>] done. task [<4>] done. task [<6>] done. task [<5>] done. task [<8>] done. task [<7>] done. task [<9>] done. task [<10>] done. task [<11>] done. task [<12>] done. task [<13>] done. task [<14>] done. task [<15>] done. task [<16>] done. task [<17>] done. task [<18>] done. task [<19>] done. task [<20>] done. $
각 부분 작업에 일련 번호를 붙였기 때문에 어느 작업이 먼저 끝나는지를 확인할 수 있습니다. 일련 번호를 부여한 순서대로 종료되지 않는 것을 보면 여러 워커가 동시에 작업을 진행하는 것이 분명해 보입니다. 워커를 한 대만 띄웠다면 1번 작업부터 20번 작업까지 번호 순으로 순차적으로 진행될테니까요. :)
또한 각 워커가 로그 파일을 제대로 남긴 것을 확인할 수 있습니다.
$ ls ... log_gearman_01.txt log_gearman_02.txt log_gearman_03.txt ...
각 로그 파일을 통해 정확히 1000개씩 파일을 처리했다는 것 역시 확인할 수 있습니다.
$ cat log_gearman_05.txt [/Users/gypark/temp/gearman/data/04001.zip] [/Users/gypark/temp/gearman/data/04002.zip] ... [/Users/gypark/temp/gearman/data/04999.zip] [/Users/gypark/temp/gearman/data/05000.zip]
소요 시간
이제 우리의 가장 큰 관심사인 "얼마나 빨라졌는가?"를 살펴보겠습니다. 순차 처리를 할 때 55초가 걸렸다고 말씀드렸습니다. 그럼 워커 두 대를 써서 수행했을 때는, 딱 절반의 시간이 걸렸을까요?
단 9초 만에 모든 작업이 완료되었습니다!
어째서 이렇게까지 단축될 수 있는지 영문을 알 수가 없었습니다. 지금 이 기사를 여기까지 쓰는 시점까지는 몰랐습니다. 그런데...
무언가 이상하다?!
워커가 한 대밖에 없는 경우는 어떨까요? 이 경우는 순차 처리하는 것과 다를 바가 없고 게다가 서버와 워커 사이의 통신 등의 오버헤드가 있으니 거의 비슷하거나 더 느릴 것 같습니다.
그런데 막상 실행해보니까 소요 시간은 14초!
여전히 순차 처리 스크립트에 비해 압도적으로 빠르더군요. 이건 아무래도 이상하다 싶어서, 순차 처리 스크립트 쪽을 수정해보았습니다. 2만 번의 루프를 도는 것을 Gearman을 쓸 때처럼 천 번씩 20회 반복을 시켜보기도 하고, 렉시컬 변수의 스코프를 조절해보기도 하고, 로그 파일을 나눠서 기록하게 해보기도 하다가 결국은 무엇을 발견했냐 하면...
Archive::Zip
앞에서 소개한 순차 처리 스크립트를 살펴보면 다음과 같은 작업을 수행합니다.
- 루프 진입 전
Archive::Zip객체 생성 - 해당 객체가 반복문을 2만 번 돌면서 계속
read()로 파일을 읽고 extractMemberWithoutPaths()로 특정 파일을 추출하는 과정을 반복
이 때 반복문을 계속해서 순회함에 따라 extractMemberWithoutPaths()
메소드의 수행 시간이 점점 길어지는 것을 발견했습니다.
제 MacOS X 시스템에서 Time::HiRes 모듈의 시간 측정 루틴이
얼마나 작은 단위까지 측정할 수 있는지는 잘 모르겠으나 이 모듈을 사용한
측정 결과에 따르면 초반에는 extractMemberWithoutPaths() 메소드를
수행하는데 400us, 즉 0.0004초 안팎이던 것이 루프를 5천 번 돌 때는 1ms,
1만 번 돌 때는 2ms, 2만 번째 돌 무렵에는 5ms 이상
즉 처음에 비해 열 배 이상 시간이 소요되더군요.
그래서 다음 코드를 반복문 안으로 넣어 매번 반복문을 순회할 때마다 새로 객체를 만들게 했더니 이제 실행 시간이 15초 정도로 줄어드는 것을 확인할 수 있었습니다.
my $zip = Archive::Zip->new();
좀 더 정확히 말하면, 2만 번의 반복문에서 매번 객체를 만드니 19초 정도 걸렸고, Gearman을 쓰는 경우와 최대한 유사하게, 루프를 천 번 도는 동안은 하나의 객체를 재사용하고 천 번째마다 새로 객체를 만들게 했더니 워커 1대를 쓰는 경우와 거의 비슷하게 15초 정도가 나왔습니다.
결국 제가 이 기사를 쓰기 시작할 때는 Gearman의 신통한 수행 속도를 소개하려고 했던 것인데 기사를 쓰는 도중에 전혀 예상치 못했던 다른 모듈의 문제점을 발견해버리고 말았습니다. :-) 그리고 가슴 아프게도 Gearman의 임팩트가 작아져버리게 되었네요.
제대로 된 소요 시간 비교
어쨌거나 이제 제대로 된 비교를 할 수 있게 되었으니 최종적인 테스트 결과를 정리해보겠습니다.
실험 환경은 다음과 같습니다.
- 맥북 프로, 2.4GHz Intel Core i7, 8GB RAM, SSD
- Perl 5.18, Gearman 1.11
- zip 파일 2만 개
각 단계마다 3번씩 수행한 평균 실행 소요 시간은 다음과 같습니다.
| 순차처리 | 1워커 | 2워커 | 3워커 | 4워커 | 5워커 | 6워커 |
|---|---|---|---|---|---|---|
| 14.81 | 14.61 | 9.04 | 8.57 | 6.64 | 5.83 | 5.78 |
그래프로 나타내면 다음과 같습니다.
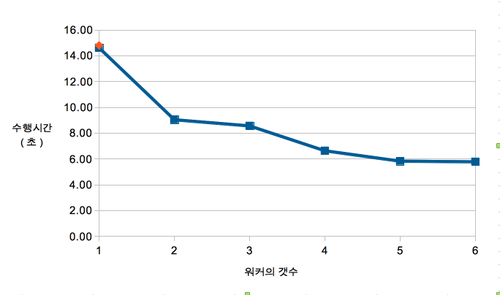 그림 1. 워커의 수에 따른 실행 소요 시간 (원본)
그림 1. 워커의 수에 따른 실행 소요 시간 (원본)
워커가 1대일 경우는 직관적으로 생각할 수 있듯이 순차 처리의 경우와 거의 비슷합니다. 워커가 2대가 되면 1대의 경우보다 1.6배 정도 빨라집니다. 2배로 빨라지면 참 좋겠지만 아무래도 이런저런 오버헤드 때문에 무리이겠죠. 워커가 3대인 경우는 2대와 큰 차이가 없으나 4대가 되면 다시 빨라집니다. 이것은 아마도 부분 작업의 갯수가 20개인데 3개의 워커가 나눠가지면 6바퀴 만으로 끝나지 않고 한 바퀴를 더 돌아야 하고 4개의 워커가 나눠가지면 5바퀴 만에 정확히 끝나는 것 때문에 생기는 현상이 아닐까 추측합니다. 어쨌거나 워커가 1대에서 2대로 느는 것에 비해서 2대에서 4대로 늘 때는 속도 향상 효과가 더 줄어드는데 CPU를 최대한 쓸 수 있느냐 I/O에서 병목이 걸리느냐 등등 영향을 미치는 요건은 여러 가지가 있을 것입니다만 이 기사에서 그런 부분까지는 제대로 따져보지는 않았습니다.
정리하며
사실 이번에 제가 했던 작업은 굳이 Gearman을 사용하지 않더라도 그저 20,000개의 파일을 10,000개씩 나눠서 순차 처리 프로세스를 동시에 두 개를 실행하여 간단히 소요 시간을 단축시킬 수 있을지도 모릅니다. 이 기사를 작성하는 도중에 이것도 해봤는데 실제로도 제일 빨랐습니다. :-)
그렇지만 전체 작업 중에 일부분만을 분산 처리해야 된다거나 또는 처리 결과를 다시 받아서 추가적인 작업을 해야하는 경우, 여러 컴퓨터를 동시에 작업에 투입하고 싶은 경우, 또 작업 대상의 갯수를 미리 알 수 없어서 정적으로 분배하기가 곤란한 경우라면 작업 분할과 분배를 일관성 있게 처리할 수 있는 이런 프레임워크를 사용하는 것이 간편할 것입니다. 실제 사용 사례도 작년 기사에서 언급이 되고 있지요.
시간이 오래 걸리는 순차 반복 작업을 할 일이 생겼을 때 이 기사가 도움이 되기를 기원해 봅니다. ;-)
- 크리스마스 달력이란
- 펄 크리스마스 달력 #2010
- 펄 크리스마스 달력 #2011
- 펄 크리스마스 달력 #2012
- Perl Advent Calendar
- Perl 6 Advent Calendar
- Perl Catalyst Advent Calendar
- Perl Dancer Advent Calendar
- Future Advent Calendar
- 일본 Perl Advent Calendar
- 일본 Mojolicious Advent Calendar
- Sysadmin Advent Calendar
- 펄.kr
- 네이버 펄 카페
- IRC #perl-kr 채팅
- 한국펄워크샵 2008



{kind=link}
Artwork by
@namanvara,
Hyungsuk Hong
& Inkyung Park.
Designed by
Hojung Youn
& Keedi Kim.
Articles by
Seoul Perl Mongers.
Edited by
Keedi Kim.
Hosting generously sponsored by
Yuni Kim.
Sponsored by
SILEX.
.-''' __ __
/ \/ \/ \
=-_- |
\. -____- / \
// /|| ''
//| //||
== = == ==