
열네번째 날: Perl로 한글의 모든 글자를 출력해보자
저자
@studioego - 평범한 자바 개발자입니다. 어릴 때 남들은 영어를 배울 때, 혼자서 한자를 배웠던 사람. 한자(漢字, 汉字, Chinese Character)에 대하여 관심이 많으며, 동아시아 언어 처리에 관심이 많음. 취미로 일본어와 중국어를 열심히 공부하고 있습니다. 유니코드 한자관련 내용에 흥미가 있어 유니코드 컨소시엄의 후원 문자(Adopted Characters)에 후원을 하기도 했습니다. GNOME gucharmap 9.0.2버전부터 한자에 대한 한글표기와 베트남어 표기를 추가(버그질라, 소스 코드)한 오픈소스 기여자(contributer), 자유 소프트웨어 개발자입니다. sungdh86+git at gmail.com
시작하며
이 글은 O’Reilly의 Learning Perl 책의 저자인 brian d foy씨가 운영하는 Learning Perl 6 블로그의 Quick Tip #1: User-defined infinite sequences과 Quick Tip #12: Unicode Helper Apps의 내용을 참고하여 만들었습니다. 저는 문자 특히 한자(漢字/汉字)에 대하여 관심이 많은 사람입니다. 그래서 한자 처리에 대한 내용을 찾다보니 Perl이란 언어에 대하여 관심을 가지게 되었습니다. 한자 처리에 관심을 가지게 되니 자연스럽게 한글 처리에도 관심을 가지게 되었습니다. 일곱째 날 기사에서는 Perl 5와 Perl 6를 이용해서 유니코드의 코드 포인트로 해당 유니코드 글자를 출력하는 법을 확인했습니다. 이번에는 한글의 모든 문자를 출력하는 방법에 대하여 확인해볼까요?
준비물
Perl 6를 설치합니다. 그리고 Perl 5도 있으면 Perl 6와 어떤 차이가 있는지 비교할 수 있으니 금상첨화겠죠?
한글과 유니코드 코드 포인트
유니코드(Unicode)와 코드 포인트(code point)에 대해서는
일곱째 날: Perl로 유니코드(Unicode) 코드 포인트(code point)에 해당하는 글자를 확인해보자 기사를 참고하세요.
유니코드 문자의 경우는 문자의 코드값를 표기할 때 코드 포인트를 사용하며, U+[16진수 숫자]로 표시합니다.
예를 들어 A의 유니코드 값은 U+0041로 표기 하며,
한글 역시 다른 유니코드와 마찬가지로 코드 포인트로 표현합니다.
한글 음절, 한글 자모 모두 코드 포인트로 등록되어있죠.
자모는 초성, 중성, 종성으로 나뉘며, 초성은 U+1100부터 U+115E까지의 범위를,
중성은 U+1161부터 U+11A7까지의 범위를,
종성은 U+11A8부터 U+11FF까지의 범위를 가집니다.
예를 들어, 음절 가의 코드 포인트는 U+AC00입니다.
음절 각의 코드 포인트는 U+AC01이며, 초성과 중성, 종성 3가지로 분해해 ㄱㅏㄱ으로 표시할 수 있습니다.
이 때 분리한 초성 ㄱ의 코드 포인트는 U+1100,
중성 ㅏ의 코드 포인트는 U+1161, 종성 ㄱ의 코드 포인트는 U+11A8입니다.
유니코드 블록 정의 파일을 살펴보면 유니코드 문자 집합의 범위를 확인할 수 있습니다. 파일의 내용을 일부만 살펴보면 다음과 같습니다.
# Blocks-9.0.0.txt # Date: 2016-02-05, 23:48:00 GMT [KW] # © 2016 Unicode®, Inc. # For terms of use, see http://www.unicode.org/terms_of_use.html # # Unicode Character Database # For documentation, see http://www.unicode.org/reports/tr44/ # # Format: # Start Code..End Code; Block Name (생략) 0000..007F; Basic Latin 0080..00FF; Latin-1 Supplement 0100..017F; Latin Extended-A 0180..024F; Latin Extended-B 0250..02AF; IPA Extensions 02B0..02FF; Spacing Modifier Letters 0300..036F; Combining Diacritical Marks (생략) 20000..2A6DF; CJK Unified Ideographs Extension B 2A700..2B73F; CJK Unified Ideographs Extension C 2B740..2B81F; CJK Unified Ideographs Extension D 2B820..2CEAF; CJK Unified Ideographs Extension E 2F800..2FA1F; CJK Compatibility Ideographs Supplement E0000..E007F; Tags E0100..E01EF; Variation Selectors Supplement F0000..FFFFF; Supplementary Private Use Area-A 100000..10FFFF; Supplementary Private Use Area-B # EOF
유니코드 전체 코드 중 한글 집합의 범위만 확인하고 싶다면 다음 명령을 실행해보세요.
$ curl http://ftp.unicode.org/Public/UNIDATA/Blocks.txt 2>/dev/null | grep Hangul 1100..11FF; Hangul Jamo 3130..318F; Hangul Compatibility Jamo A960..A97F; Hangul Jamo Extended-A AC00..D7AF; Hangul Syllables D7B0..D7FF; Hangul Jamo Extended-B $
한글 음절을 모두 출력해보자
Perl 6로 한글 음절(Hangul Syllables) 전체를 출력해봅시다. 이 때 터미널 인코딩은 UTF-8로 설정했다고 가정합니다.
my %hash;
%hash<hangulSyllables> := :16("AC00") ... :16("D7AF");
for %hash<hangulSyllables> {
say "U+", ($_).base(16), " ", chr($_);
}
Perl 5의 경우 코드는 다음과 같습니다. 이 때 터미널 인코딩은 UTF-8로 설정했다고 가정합니다.
use open ":std", ":encoding(UTF-8)";
my @blocks = ( hex("AC00") .. hex("D7AF") );
for my $block (@blocks) {
printf "U+%X %s\n", $block, chr($block);
}
use open ... 구문을 빼먹는다면 Wide character in printf at ...과 같은 경고가 발생하므로
Perl 5에서는 Perl 6와 다르게 유니코드 설정을 명시적으로 해줘야 합니다.
두 코드 모두의 실행 결과는 동일합니다.
U+AC00 가 U+AC01 각 U+AC02 갂 U+AC03 갃 U+AC04 간 U+AC05 갅 (생략) U+D79E 힞 U+D79F 힟 U+D7A0 힠 U+D7A1 힡 U+D7A2 힢 U+D7A3 힣 U+D7A4 U+D7A5 U+D7A6 U+D7A7 U+D7A8 U+D7A9 U+D7AA U+D7AB U+D7AC U+D7AD U+D7AE U+D7AF
앞의 코드는 가에서 힣까지 미리 조합된 한글 전체 음절을 화면에 출력합니다.
여기서 유니코드에서 한글 음절에 대하여 11,172자를 할당했다는 것을 확인할 수 있습니다.
모든 유니코드 블록 범위는 (cp MOD 16) = 0인 값으로 시작해서 (cp MOD 16) = 15인 값으로 끝납니다.
따라서 한글의 가에서 힣까지의 11,172자는 ( 698 * 16 + 4 )에 해당하고,
남은 12개의 영역은 할당 후 비워둔 영역인 것입니다.
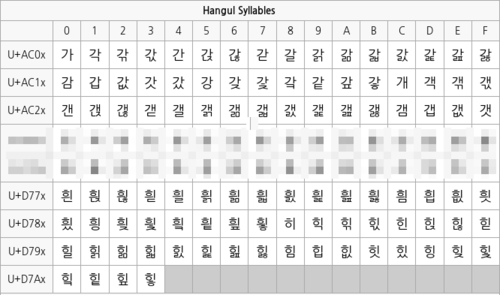 그림 1. 유니코드 한글 블록 (원본)
그림 1. 유니코드 한글 블록 (원본)
정리하며
Perl 6가 새로 나오는 것을 보면서 Perl 5와 Perl 6의 차이에 대하여 확인하다보니 Learning Perl 6 블로그의 Quick Tip 1: User-defined infinite sequences 글이 눈에 띄더군요. 해당 글을 읽고 정리하며 유니코드 개념과 코드 포인트는 물론 유니코드 블록의 개념도 알게 되었습니다. 유니코드 블록을 이용하여 블록 단위로 된 코드 포인트에 할당된 글자를 모두 출력하는 방법을 알게 되었습니다. 유니코드는 전 세계의 모든 문자를 다룰 수 있도록 세심하게 설계된 만큼 코드 포인트를 통해 배치된 순서에도 해당 글자의 정렬이라던가 등의 고려가 되어있습니다. 유니코드의 코드 포인트와 블록을 이용해 원하는 글자를 확인 및 추려내는 방법을 안다면, 추후 다국어를 처리할 일이 있을 때 유용하게 사용할 수 있을 것입니다. :)
참고자료
- Learning Perl 6 블로그의 Quick Tip #1: User-defined infinite sequences
- Learning Perl 6 블로그의 Quick Tip #12: Unicode Helper Apps
- Unicode Consortium
- Unicode 9.0 전체 코드 차트
- Unicode Character Database Block정의
- Unicode Unihan Database
- Unicode Character Database
- Unicode Unihan Lookup
- Announcing The Unicode® Standard, Version 9.0
- 네이버 Hello world의 한글 인코딩의 이해 1편: 한글 인코딩의 역사와 유니코드
- 네이버 Hello world의 한글 인코딩의 이해 2편: 유니코드와 Java를 이용한 한글 처리
- Perl 6 Advent Calendar 2013 Day 15 - Numbers and ways of writing them
- Adobe 블로그의 Combining Jamo Test #1 - Please Ignore
- Adobe 블로그의 Combining Jamo Test #2 - Please Ignore
- Adobe 블로그의 Combining Jamo Test #3
- Adobe 블로그의 Source Han Sans Development: Archaic Hangul
- 크리스마스 달력이란
- 펄 크리스마스 달력 #2010
- 펄 크리스마스 달력 #2011
- 펄 크리스마스 달력 #2012
- 펄 크리스마스 달력 #2013
- 펄 크리스마스 달력 #2014
- 펄 크리스마스 달력 #2015
- Perl Advent Calendar
- Perl 6 Advent Calendar
- Perl Catalyst Advent Calendar
- Perl Dancer Advent Calendar
- Future Advent Calendar
- 일본 Perl 입학식 Advent Calendar
- 일본 Perl 5 Advent Calendar
- 일본 Perl 6 Advent Calendar
- 일본 Mojolicious Advent Calendar
- Sysadmin Advent Calendar
- Web Design & Devlopment Advent Calendar
- 한국 루비 크리스마스 달력
- 이상한 모임 크리스마스 달력
- 펄.kr
- 네이버 펄 카페
- IRC #perl-kr 채팅
- 한국펄워크샵 2012



{kind=link}
X-mas tree
& Llama
ASCII Art by ASCII Art Farts.
Computer ASCII Art by Chris.com.
Cup ASCII Art by ascii.co.uk.
Candle ASCII Art by heartnsoul.com.
Font ASCII Art by ASCII Art Farts.
Text ASCII Art by patorjk.com.
Artwork by
Inkyung Park
& Keedi Kim.
Designed by
Hojung Youn
& Keedi Kim.
Articles by
Seoul Perl Mongers.
Edited by
Keedi Kim.
Hosting sponsored by
SILEX.
Sponsored by
SILEX.
.-''' __ __
/ \/ \/ \
=-_- |
\. -____- / \
// /|| ''
//| //||
== = == ==